Zwei Strategien bin ich bisher bei meiner Addition aller Elemente eines std::vector gefolgt. Zum einen habe ich die ganze Summation in einem Thread ausgeführt (Single-Threaded: Summe der Elemente eines Vektors), zum anderen alle Threads auf einer gemeinsamen Summations-Variable (Multithreaded: Addition mit einer geteilten Variable) agieren lassen. Gerade die zweite Strategie war sehr naiv. In diesem Artikel werde ich meine Erkenntnisse aus beiden Artikeln anwenden. Mein Ziel wird es daher sein, die Threads möglichst unabhängig ihre Arbeit ausführen zu lassen und die Synchronisation der Threads auf der Summations-Variable zu minimieren.
Um die Threads unabhängig voneinander ihre Arbeit ausführen zu lassen und ihre Synchronisation zu minimieren, bitten sich mehrere Strategien an. Lokale Variablen, threadlokale Daten aber auch Tasks sind vielversprechende Ansätze. Ich bin auf die Ergebnisse gespannt.
Die Vorgehensweise
Meine Vorgehensweise unterscheidet sich nicht von der des letzten Artikels. Wieder kommt mein Desktop PC mit dem GCC-Compiler und 4 Kernen und mein Laptop mit dem cl.exe-Compiler und zwei Kernen zum Einsatz. Alle Ergebnis gibt es in bekannter Manier mit und ohne maximale Optimierung. Das genauere Setup meiner Compiler kannst du im Artikel Threadsicheres Initialisieren eines Singletons nachlesen.
Lokale Variable
Da jeder Thread eine lokale Summations-Variable besitzt, kann er ohne Synchronisation seine Rechenaufgabe erledigen. Es ist nur notwendig, dass alle lokalen Summations-Variablen zusammenaddiert werden. Die Addition der Zwischenergebnisse stellt den kritischen Bereich dar, den es zu schützen gilt. Das geht natürlich in verschiedenen Variationen. Eine Bemerkung noch vornweg. Da für das Gesamtergebnis nur vier Additionen verwendet werden, ist die Performanz fast unabhängig davon, welche Synchronisationsmechanismen ich verwende. Trotzdem werde ich einen std::lock_guard, eine atomare Operation mit Sequenzieller Konsistenz und mit Relaxed-Semantik vorstellen.
std::lock_guard
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
// localVariable.cpp #include <mutex> #include <chrono> #include <iostream> #include <random> #include <thread> #include <utility> #include <vector> constexpr long long size= 100000000; constexpr long long firBound= 25000000; constexpr long long secBound= 50000000; constexpr long long thiBound= 75000000; constexpr long long fouBound= 100000000; std::mutex myMutex; void sumUp(unsigned long long& sum, const std::vector<int>& val, unsigned long long beg, unsigned long long end){ unsigned long long tmpSum{}; for (auto i= beg; i < end; ++i){ tmpSum += val[i]; } std::lock_guard<std::mutex> lockGuard(myMutex); sum+= tmpSum; } int main(){ std::cout << std::endl; std::vector<int> randValues; randValues.reserve(size); std::mt19937 engine; std::uniform_int_distribution<> uniformDist(1,10); for ( long long i=0 ; i< size ; ++i) randValues.push_back(uniformDist(engine)); unsigned long long sum{}; auto start = std::chrono::system_clock::now(); std::thread t1(sumUp,std::ref(sum),std::ref(randValues),0,firBound); std::thread t2(sumUp,std::ref(sum),std::ref(randValues),firBound,secBound); std::thread t3(sumUp,std::ref(sum),std::ref(randValues),secBound,thiBound); std::thread t4(sumUp,std::ref(sum),std::ref(randValues),thiBound,fouBound); t1.join(); t2.join(); t3.join(); t4.join(); std::chrono::duration<double> dur= std::chrono::system_clock::now() - start; std::cout << "Time for addition " << dur.count() << " seconds" << std::endl; std::cout << "Result: " << sum << std::endl; std::cout << std::endl; } |
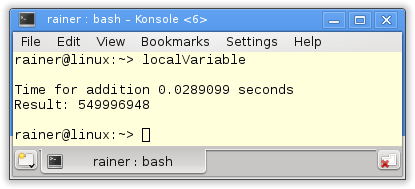
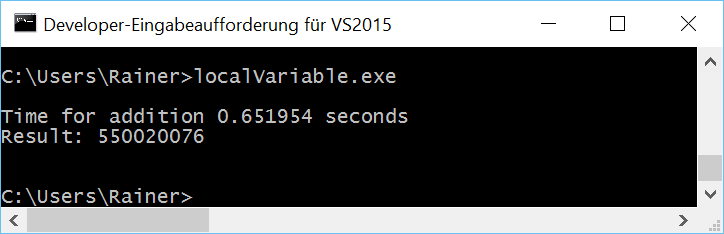
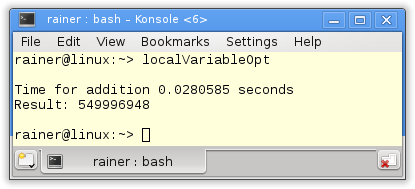
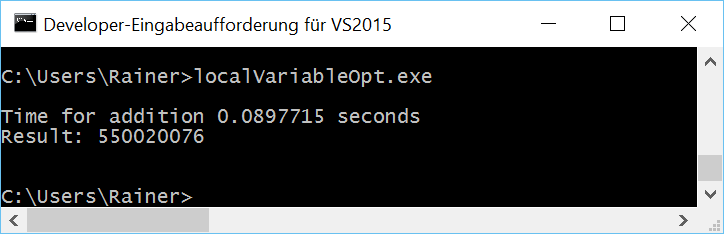
Die entscheidenden Zeilen des Beispiels sind die Zeilen 25 - 26. In dieser wird der lokale Summations-Wert tmpSum auf die gemeinsame Variable sum addiert. Dies ist genau die Stelle, an denen die Beispiele mit den lokalen Variablen variieren.
Keine Optimierung
Maximale Optimierung
Atomare Operationen mit Sequenzieller Konsistenz
Die erste Optimierung besteht darin, die durch ein Lock geschützte Summations-Variable sum durch eine atomare Variable zu ersetzen.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
// localVariableAtomic.cpp #include <atomic> #include <chrono> #include <iostream> #include <random> #include <thread> #include <utility> #include <vector> constexpr long long size= 100000000; constexpr long long firBound= 25000000; constexpr long long secBound= 50000000; constexpr long long thiBound= 75000000; constexpr long long fouBound= 100000000; void sumUp(std::atomic<unsigned long long>& sum, const std::vector<int>& val, unsigned long long beg, unsigned long long end){ unsigned int long long tmpSum{}; for (auto i= beg; i < end; ++i){ tmpSum += val[i]; } sum+= tmpSum; } int main(){ std::cout << std::endl; std::vector<int> randValues; randValues.reserve(size); std::mt19937 engine; std::uniform_int_distribution<> uniformDist(1,10); for ( long long i=0 ; i< size ; ++i) randValues.push_back(uniformDist(engine)); std::atomic<unsigned long long> sum{}; auto start = std::chrono::system_clock::now(); std::thread t1(sumUp,std::ref(sum),std::ref(randValues),0,firBound); std::thread t2(sumUp,std::ref(sum),std::ref(randValues),firBound,secBound); std::thread t3(sumUp,std::ref(sum),std::ref(randValues),secBound,thiBound); std::thread t4(sumUp,std::ref(sum),std::ref(randValues),thiBound,fouBound); t1.join(); t2.join(); t3.join(); t4.join(); std::chrono::duration<double> dur= std::chrono::system_clock::now() - start; std::cout << "Time for addition " << dur.count() << " seconds" << std::endl; std::cout << "Result: " << sum << std::endl; std::cout << std::endl; } |
Ohne Optimierung
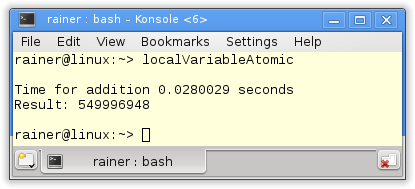
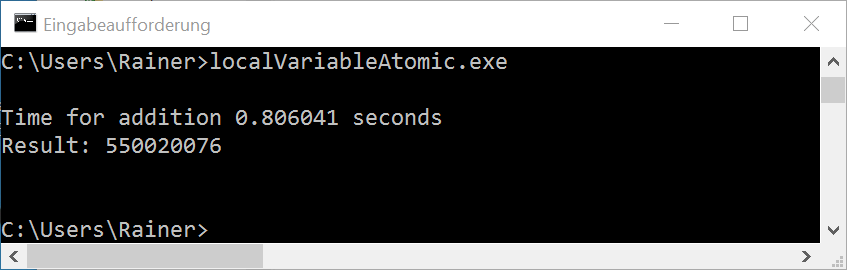
Maximale Optimierung
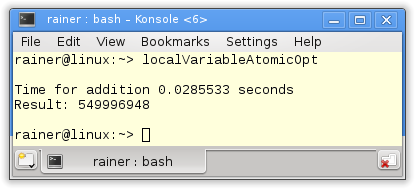
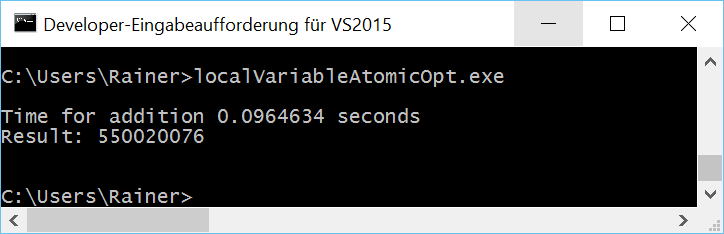
Atomare Operationen mit Relaxed-Semantik
Ein weiteres Optimierungspotential besteht darin, die atomar ausgeführte Addition mit der Relaxed-Semantik zu versehen. Das ist wohldefiniert, da es nicht entscheidend ist, in welcher Reihenfolge die Additionen stattfinden. In Zeile 23 findet die atomare Addition statt.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
// localVariableAtomicRelaxed.cpp #include <atomic> #include <chrono> #include <iostream> #include <random> #include <thread> #include <utility> #include <vector> constexpr long long size= 100000000; constexpr long long firBound= 25000000; constexpr long long secBound= 50000000; constexpr long long thiBound= 75000000; constexpr long long fouBound= 100000000; void sumUp(std::atomic<unsigned long long>& sum, const std::vector<int>& val, unsigned long long beg, unsigned long long end){ unsigned int long long tmpSum{}; for (auto i= beg; i < end; ++i){ tmpSum += val[i]; } sum.fetch_add(tmpSum,std::memory_order_relaxed); } int main(){ std::cout << std::endl; std::vector<int> randValues; randValues.reserve(size); std::mt19937 engine; std::uniform_int_distribution<> uniformDist(1,10); for ( long long i=0 ; i< size ; ++i) randValues.push_back(uniformDist(engine)); std::atomic<unsigned long long> sum{}; auto start = std::chrono::system_clock::now(); std::thread t1(sumUp,std::ref(sum),std::ref(randValues),0,firBound); std::thread t2(sumUp,std::ref(sum),std::ref(randValues),firBound,secBound); std::thread t3(sumUp,std::ref(sum),std::ref(randValues),secBound,thiBound); std::thread t4(sumUp,std::ref(sum),std::ref(randValues),thiBound,fouBound); t1.join(); t2.join(); t3.join(); t4.join(); std::chrono::duration<double> dur= std::chrono::system_clock::now() - start; std::cout << "Time for addition " << dur.count() << " seconds" << std::endl; std::cout << "Result: " << sum << std::endl; std::cout << std::endl; } |
Ohne Optimierung

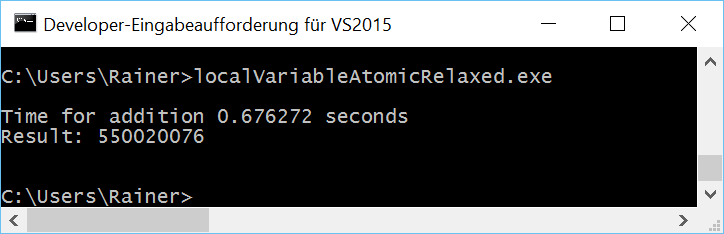
Maximale Optimierung


Eine ähnliche Strategie wie mit lokalen Variablen verfolge ich mit threadlokalen Daten.
Threadlokale Daten
Threadlokale Daten sind Daten, die für jeden Thread automatisch erzeugt werden und jedem Thread exklusiv gehören. Sie werden genau dann erzeugt, wenn sie benötigt werden. Damit sind threadlokale Daten ein idealer Kandidat für die lokale Summations-Variable tmpSum.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
// threadLocal.cpp #include <atomic> #include <chrono> #include <iostream> #include <random> #include <thread> #include <utility> #include <vector> constexpr long long size= 100000000; constexpr long long firBound= 25000000; constexpr long long secBound= 50000000; constexpr long long thiBound= 75000000; constexpr long long fouBound= 100000000; thread_local unsigned long long tmpSum= 0; void sumUp(std::atomic<unsigned long long>& sum, const std::vector<int>& val, unsigned long long beg, unsigned long long end){ for (auto i= beg; i < end; ++i){ tmpSum += val[i]; } sum.fetch_add(tmpSum,std::memory_order_relaxed); } int main(){ std::cout << std::endl; std::vector<int> randValues; randValues.reserve(size); std::mt19937 engine; std::uniform_int_distribution<> uniformDist(1,10); for ( long long i=0 ; i< size ; ++i) randValues.push_back(uniformDist(engine)); std::atomic<unsigned long long> sum{}; auto start = std::chrono::system_clock::now(); std::thread t1(sumUp,std::ref(sum),std::ref(randValues),0,firBound); std::thread t2(sumUp,std::ref(sum),std::ref(randValues),firBound,secBound); std::thread t3(sumUp,std::ref(sum),std::ref(randValues),secBound,thiBound); std::thread t4(sumUp,std::ref(sum),std::ref(randValues),thiBound,fouBound); t1.join(); t2.join(); t3.join(); t4.join(); std::chrono::duration<double> dur= std::chrono::system_clock::now() - start; std::cout << "Time for addition " << dur.count() << " seconds" << std::endl; std::cout << "Result: " << sum << std::endl; std::cout << std::endl; } |
In Zeile 18 erkläre ich die threadlokale Variable tmpSum. Diese verwende ich anschließend in den Additionen in den Zeilen 22 und 24. Der feine Unterschied zwischen der threadlokalen und der lokalen Variable in den vorherigen Beispielen ist, dass die Lebenszeit der threadlokalen Variable an ihren Thread, dass die Lebenszeit der lokalen Variable an ihren Gültigkeitsbereich (Scope) gebunden ist.
Ohne Optimierung
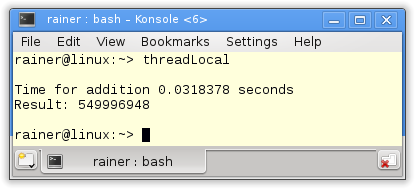
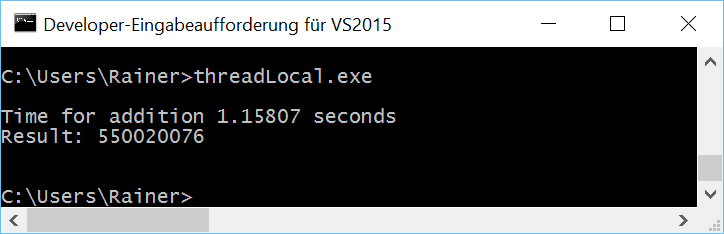
Maximale Optimierung
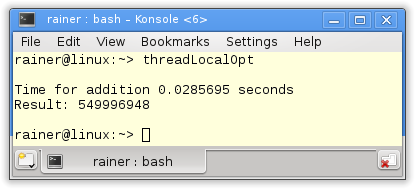
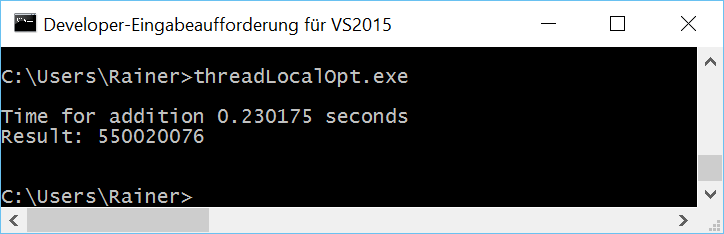
Lassen sich die Teilsummen des Vektors auch ohne explizite Synchronisation schnell auf mehreren Threads berechnen? Ja.
Tasks
Dank Tasks ist die ganze Rechnerei auch ohne Synchronisation möglich. Erlauben sie es doch, jede Rechenaufgabe in einem seperaten Thread zu erledigen und das Ergebnis explizit abzuholen. Die Details zu Tasks gibt es hier. In dem konkreten Beispiel benötige ich die Mächtigkeit des Paars Promise und Future.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 |
// tasks.cpp #include <chrono> #include <future> #include <iostream> #include <random> #include <thread> #include <utility> #include <vector> constexpr long long size= 100000000; constexpr long long firBound= 25000000; constexpr long long secBound= 50000000; constexpr long long thiBound= 75000000; constexpr long long fouBound= 100000000; void sumUp(std::promise<unsigned long long>&& prom, const std::vector<int>& val, unsigned long long beg, unsigned long long end){ unsigned long long sum={}; for (auto i= beg; i < end; ++i){ sum += val[i]; } prom.set_value(sum); } int main(){ std::cout << std::endl; std::vector<int> randValues; randValues.reserve(size); std::mt19937 engine; std::uniform_int_distribution<> uniformDist(1,10); for ( long long i=0 ; i< size ; ++i) randValues.push_back(uniformDist(engine)); std::promise<unsigned long long> prom1; std::promise<unsigned long long> prom2; std::promise<unsigned long long> prom3; std::promise<unsigned long long> prom4; auto fut1= prom1.get_future(); auto fut2= prom2.get_future(); auto fut3= prom3.get_future(); auto fut4= prom4.get_future(); auto start = std::chrono::system_clock::now(); std::thread t1(sumUp,std::move(prom1),std::ref(randValues),0,firBound); std::thread t2(sumUp,std::move(prom2),std::ref(randValues),firBound,secBound); std::thread t3(sumUp,std::move(prom3),std::ref(randValues),secBound,thiBound); std::thread t4(sumUp,std::move(prom4),std::ref(randValues),thiBound,fouBound); auto sum= fut1.get() + fut2.get() + fut3.get() + fut4.get(); std::chrono::duration<double> dur= std::chrono::system_clock::now() - start; std::cout << "Time for addition " << dur.count() << " seconds" << std::endl; std::cout << "Result: " << sum << std::endl; t1.join(); t2.join(); t3.join(); t4.join(); std::cout << std::endl; } |
In den Zeile 37 - 45 definiere ich vier Promise und erzeuge aus diesen die assoziierten Promise. Die Promise verschiebe ich in den Zeile 50 - 53 in separate Threads. Promise können nur verschoben werden, daher wende ich std::move an. Das Arbeitspaket der Threads, die Funktion sumUp in Zeile 18 - 24, erhält als erstes Argument einen Promise. Diesen verwendet sumUp als Rvalue Referenz um die durch std::move erzeugt Rvalue Referenz zu binden. In den blockierenden get-Aufrufen in der Zeile 55 holen die Future das Ergebnis ihres Promise ab.
Ohne Optimierung

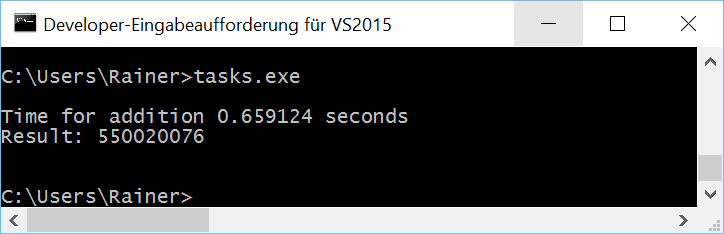
Maximale Optimierung

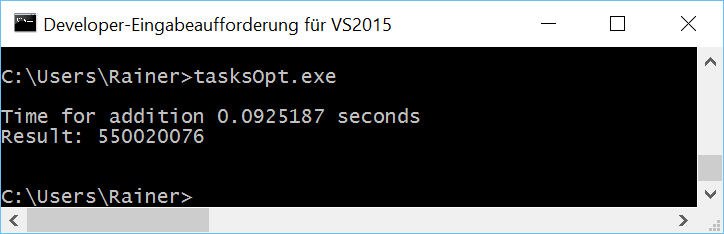
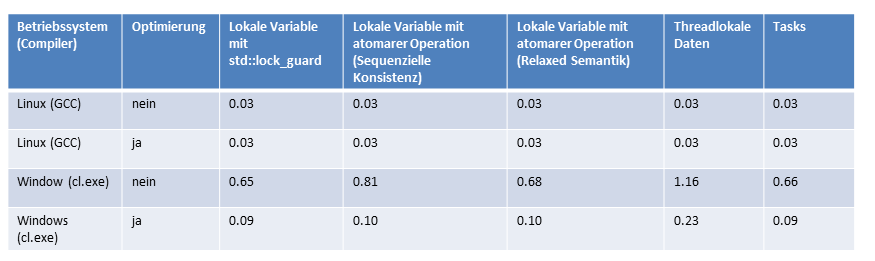
Nochmals als Zahlen im Überblick.
Der Überblick
Wie bereits vorweggenommen, unterscheiden sich unter Linux die Zahlen der verschiedenen Variationen nicht signifikant. Das ist auch nicht verwunderlich. Wende ich doch immer die gleiche einfache Strategie an: Berechne die Summe ohne Synchronisation und addiere die lokalen Ergebnisse. Bei der Bildung der Gesamtsumme muss ich natürlich synchronisieren. Verwundert hat mich allerdings, dass ich durch die Übersetzung mit maximaler Optimierung keinen großen Performanzvorteil erzielen konnte.
Bei Windows ist die Geschichte total anders. Zum einen macht es einen großen Unterschied, ob ich die Programme mit maximaler und ohne Optimierung übersetze, zum anderen ist Windows auf meinem Rechner deutlich langsamer als Linux. Das will ich aber nicht überbewerten, da meine Linux Plattform 4, meine Windows Plattform 2 Kerne unter der Haube hat.
Wie geht's weiter?
Im nächsten Artikel möchte ich die Zahlen und Ergebnisse der drei Strategien zur Berechnung der Summe eines Vektors nochmals Revue passieren lassen.
 Go to Leanpub/cpplibrary "What every professional C++ programmer should know about the C++ standard library". Hole dir dein E-Book. Unterstütze meinen Blog.
Go to Leanpub/cpplibrary "What every professional C++ programmer should know about the C++ standard library". Hole dir dein E-Book. Unterstütze meinen Blog.






Weiterlesen...