Nachdem ich in den letzten drei Artikel die Summe eines Vektors in drei verschiedenen Strategien berechnet habe, möchte ich mit diesem Artikel mein Fazit ziehen.
Die drei Strategien
Alle Zahlen nochmals im Überblick. Zuerst die Single-Threaded Variante, dann die Variante mit mehreren Threads und einer geteilten Summations-Variable und zuletzt die Variante, in der ich die Synchronisation der vier Threads auf ein Minimum reduziert habe. Ich muss zugeben, dass ich mir insbesondere von der letzten Variante deutlich mehr versprochen habe.
Single-Threaded (1)
Mehrere Threads mit einer geteilten Summations-Variable (2)

Mehrere Threads mit minimaler Synchronisation (3)
Meine Beobachtungen
Der Einfachheit halber will ich mich in meinen Beobachtungen auf die Programme unter Linux beziehen. Bei meiner Analyse hat mich Andreas Schäfer (https://plus.google.com/u/0/+AndreasSch%C3%A4fer_gentryx) sehr stark unterstützt. Vielen Danke für die tiefen Einsichten.
Single-Threaded
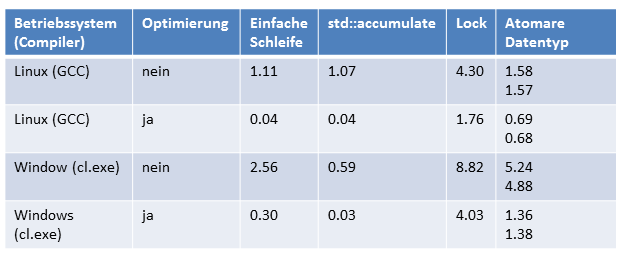
Die Range-basierte for-Anweisung und der STL-Algortihmus std::accumulate spielen in der gleichen Liga. Das trifft sowohl auf die optimierte und maximale optimierten Programme zu. Sehr interessant ist der Grund, das die maximale optimierten Varianten nahezu um den Faktor 30 schneller sind. In Falle der Optimierung wendet der Compiler für die Summationsschleifen vektorisierte Instruktionen (SSE oder AVX) an. Das Ergebnis ist, das der Schleifenzähler jeweils um 2 (SSE) oder 4 (AVX) erhöht wird.
Mehrere Thread mit einer geteilten Summations-Variable
Die feingranulare Synchronisation auf einer gemeinsamen Variable (2) zeigt deutlich die Grenzen von mehreren Threads auf. Trotz Bruch der Sequenziellen Konsistenz mit der Relaxed-Semantik ist das Programm ca. um den Faktor 40 langsamer als seine Pendants (1) oder (3). Nicht nur aus Performanzgründen muss es daher das Ziel sein, die Synchronisation auf gemeinsamen Variablen zu minimieren.
Mehrere Threads mit minimaler Synchronisation
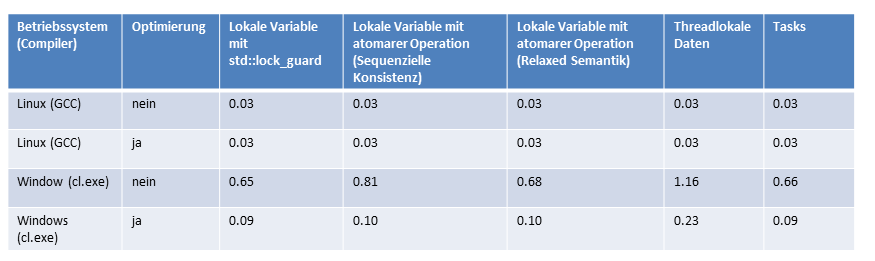
Die Summation auf minimal synchronisierten Threads (4 atomare Operationen oder Locks) (3) ist kaum schneller als die Range-basierte for-Anweisung oder std::accumulate (1). Dies gilt sogar, obwohl in der Multihreading Variante vier Threads auf vier Kernen unabhängig addieren können. Das war für mich die größte Überraschung, den ich hatte nahezu einen vierfachen Performanzgewinn in diesem Fall erwartet. Noch mehr verwundert mich, dass alle vier Kerne bei ihrer Summation nicht voll ausgelastet sind.
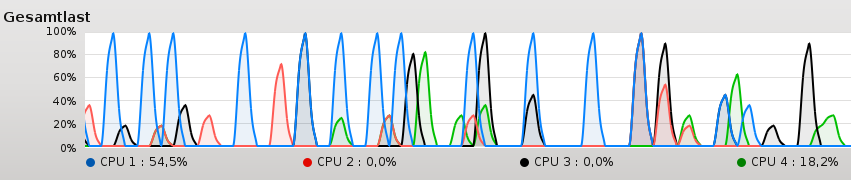
Der Grund ist einfach. Die Kerne fordern schneller die Daten vom Hauptspeicher an, als diese geliefert werden können. Oder anders ausgedrückt .Der Hauptspeicher bremst die CPU's aus.
Mein Fazit
Mein Fazit aus den vielen Performanzmessungen ist es, für eine solch einfache Operation wie die Berechnung einer Summe std::accumlate anzuwenden. Dies hat zwei Gründe. Zum einen rechtfertigt der Performanzgewinn durch Variante (3) nicht deren Aufwand, zum anderen wird C++17 mit großer Wahrscheinlichkeit ein automatisch parallelisierendes std::accumlate Algorithmus besitzen.
 Go to Leanpub/cpplibrary "What every professional C++ programmer should know about the C++ standard library". Hole dir dein E-Book. Unterstütze meinen Blog.
Go to Leanpub/cpplibrary "What every professional C++ programmer should know about the C++ standard library". Hole dir dein E-Book. Unterstütze meinen Blog.






Weiterlesen...