Wie lassen sich die Werte eines std::vector am schnellsten zusammenaddieren? Diese Frage will ich in mehreren Artikeln nachgehen. Als Referenzwert soll dabei die Addition in einem Thread dienen. In weiteren Artikel gehe ich auf atomare Variablen, Locks, Tasks und threadlokale Daten ein.
Meine Strategie
Ich werde einen std::vector mit hundert Millionen zufällig erzeugte natürliche Zahlen zwischen 1 und 10 füllen. Die Zufallszahlen erzeuge ich mit Hilfe der Gleichverteilung. Die Rechenaufgabe besteht dann darin, die Summe aller Zahlen zu berechnen.
Als Hardware kommen wieder mein Linux Desktop PC und mein Windows Laptop zum Einsatz. Mein Linux Rechner besitzt vier, mein Windows 2 Kerne. Genaueres zu den Compilern kannst du unter Threadsicheres Initialisieren eines Singleton nachlesen. Alle Programme werde ich ohne und mit maximaler Optimierung übersetzen.
Eine einfache Schleife
Die naheliegendste Strategie ist es, in einer Range-basierte for-Anweisung die Summe aller Elemente zu berechnen.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
// calculateWithLoop.cpp #include <chrono> #include <iostream> #include <random> #include <vector> constexpr long long size= 100000000; int main(){ std::cout << std::endl; std::vector<int> randValues; randValues.reserve(size); // random values std::random_device seed; std::mt19937 engine(seed()); std::uniform_int_distribution<> uniformDist(1,10); for ( long long i=0 ; i< size ; ++i) randValues.push_back(uniformDist(engine)); auto start = std::chrono::system_clock::now(); unsigned long long add= {}; for (auto n: randValues) add+= n; std::chrono::duration<double> dur= std::chrono::system_clock::now() - start; std::cout << "Time for addition " << dur.count() << " seconds" << std::endl; std::cout << "Result: " << add << std::endl; std::cout << std::endl; } |
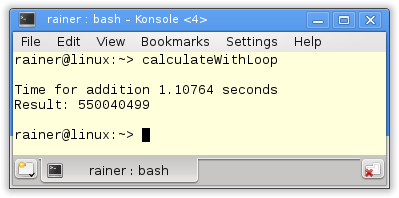
In der Zeile 26 findet die eigentliche Arbeit statt. Wie schnell sind meine Rechner?
Ohne Optimierung

Maximale Optimierung

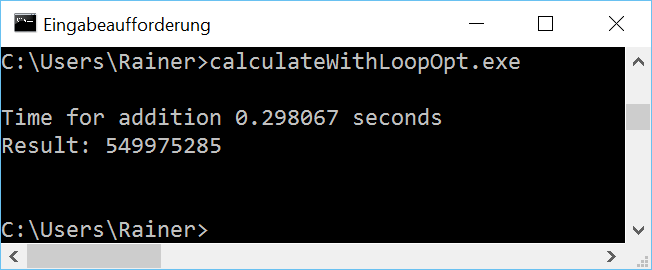
Explizite Schleifen sollten nicht verwendet werden. Meist ist ein Algorithmus der Standard Template Library (STL) die bessere Lösung. Diese Aussage gilt insbesondere für die Range-basierte for-Anweisung unter Windows, da sie noch einiges an Optimierungspotential besitzt.
Die STL mit std::accumulate
std::accumulate ist das Mittel der Wahl, wenn es darum geht, die Summe zu berechnen.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
// calculateWithStd.cpp #include <algorithm> #include <chrono> #include <iostream> #include <numeric> #include <random> #include <vector> constexpr long long size= 100000000; int main(){ std::cout << std::endl; std::vector<int> randValues; randValues.reserve(size); // random values std::random_device seed; std::mt19937 engine(seed()); std::uniform_int_distribution<> uniformDist(1,10); for ( long long i=0 ; i< size ; ++i) randValues.push_back(uniformDist(engine)); auto start = std::chrono::system_clock::now(); unsigned long long add= std::accumulate(randValues.begin(),randValues.end(),0); std::chrono::duration<double> dur= std::chrono::system_clock::now() - start; std::cout << "Time for addition " << dur.count() << " seconds" << std::endl; std::cout << "Result: " << add << std::endl; std::cout << std::endl; } |
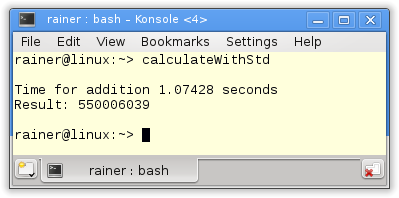
Die Zeile 27 ist die entscheidende Zeile in dem Beispiel. Die Performanz von std::accumulate entspricht der der Range-basierten for-Schleife. Dies gilt nicht für Windows.
Keine Optimierung

Maximale Optimierung
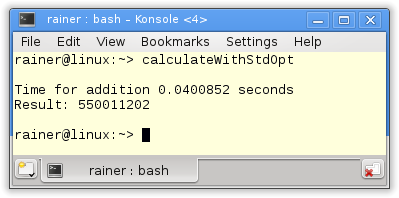
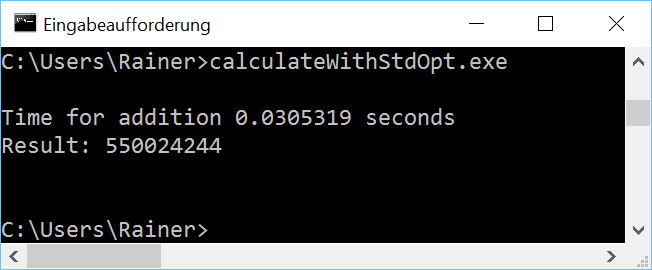
Eigentlich waren dies schon die zwei Programme, die als Referenz von die Multithreading Lösung dienen sollen. Ich finde es aber sehr interessant, die Summationsvariable add durch einen Lock bzw. eine atomaren Datentyp zu schützen.
Schutz durch ein Lock
Schütze ich den Zugriff auf die Summationsvariable add durch ein Lock, so beantwortet dies zwei Fragen.
- Wie hoch ist de Synchronisationsaufwand, den ein Lock benötigt?
- Wie performant kann ein Lock maximal sein, wenn keine konkurrierenden Zugriffe auf die gemeinsame Variable stattfinden?
Der Punkt 2 kann auch negativ formuliert werden. Sobald mehrere Threads um den gemeinsamen Zugriff auf eine geteilte Variable konkurrieren, wird der Zugriff langsamer.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
// calculateWithLock.cpp #include <chrono> #include <iostream> #include <mutex> #include <numeric> #include <random> #include <vector> constexpr long long size= 100000000; int main(){ std::cout << std::endl; std::vector<int> randValues; randValues.reserve(size); // random values std::random_device seed; std::mt19937 engine(seed()); std::uniform_int_distribution<> uniformDist(1,10); for ( long long i=0 ; i< size ; ++i) randValues.push_back(uniformDist(engine)); std::mutex myMutex; unsigned long long int add= 0; auto start = std::chrono::system_clock::now(); for (auto i: randValues){ std::lock_guard<std::mutex> myLockGuard(myMutex); add+= i; } std::chrono::duration<double> dur= std::chrono::system_clock::now() - start; std::cout << "Time for addition " << dur.count() << " seconds" << std::endl; std::cout << "Result: " << add << std::endl; std::cout << std::endl; } |
Erwartungsgemäß ist der geschützte Zugriff auf die Variable add deutlich langsamer.
Keine Optimierung
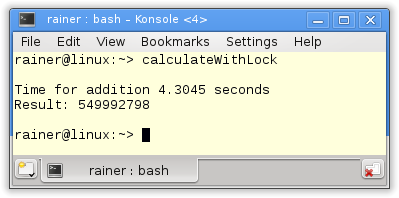
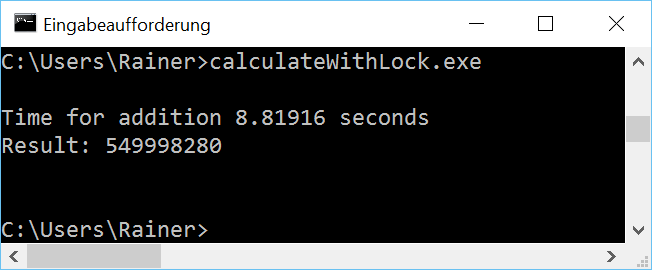
Maximale Optimierung


Während die nicht optimierte Variante mit dem Lock um den Faktor 4 - 12 langsamer ist, ist die maximale optimierte Variante um den Faktor 10 - 40 langsamer als ihr std::accumulate Pedant.
Zum Abschuss folgen noch die atomaren Datentypen.
Schutz durch einen atomaren Datentyp
Die gleiche Fragestellung wie für die Locks gelten auch für die atomaren Datentypen.
- Wie hoch ist de Synchronisationsaufwand, den ein atomarer Datentyp benötigt?
- Wie performant kann ein atomarer Datentyp maximal sein, wenn keine konkurrierenden Zugriffe auf die gemeinsame Variable stattfinden?
Darüber hinaus ist die Frage interessant, wie sich die Performanz des atomaren Datentyp gegenüber der des Locks verhält.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
// calculateWithAtomic.cpp #include <atomic> #include <chrono> #include <iostream> #include <numeric> #include <random> #include <vector> constexpr long long size= 100000000; int main(){ std::cout << std::endl; std::vector<int> randValues; randValues.reserve(size); // random values std::random_device seed; std::mt19937 engine(seed()); std::uniform_int_distribution<> uniformDist(1,10); for ( long long i=0 ; i< size ; ++i) randValues.push_back(uniformDist(engine)); std::atomic<unsigned long long> add={}; std::cout << std::boolalpha << "add.is_lock_free(): " << add.is_lock_free() << std::endl; std::cout << std::endl; auto start = std::chrono::system_clock::now(); for (auto i: randValues) add+= i; std::chrono::duration<double> dur= std::chrono::system_clock::now() - start; std::cout << "Time for addition " << dur.count() << " seconds" << std::endl; std::cout << "Result: " << add << std::endl; std::cout << std::endl; add=0; start = std::chrono::system_clock::now(); for (auto i: randValues) add.fetch_add(i,std::memory_order_relaxed); dur= std::chrono::system_clock::now() - start; std::cout << "Time for addition " << dur.count() << " seconds" << std::endl; std::cout << "Result: " << add << std::endl; std::cout << std::endl; } |
Das Programm enthält ein paar Besonderheiten. Zum einen frage ich in Zeile 26 ab, ob der atomare Datentyp ohne Lock implementiert ist. Wäre dies der Fall, müsste ich nicht zwischen Locks und atomaren Datentypen unterscheiden. Auf allen modernen Plattformen sind atomare Datentyp ohne Locks implementiert. Zum anderen berechne ich die Summe auf zwei verschiedene Arten. In Zeile 31 verwende ich den += Operator, in Zeile 42 die Methode fetch_add. Beide Varianten besitzen im Singlethreaded Fall eine vergleichbare Performanz. Für die Methode fetch_add kann aber explizit die Speicherordnung angegeben werden. Dazu im nächsten Artikel mehr.
Nun bin ich auf die Zahlen gespannt.
Keine Optimierung


Maximale Optimierung
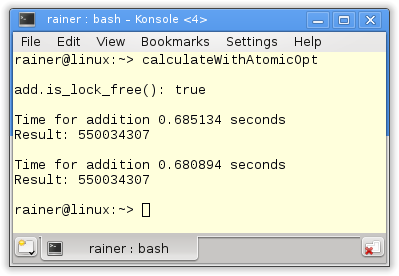
Die atomare Variante ist im Fall von Linux um den Faktor 1.5, im Fall von Windows um den Faktor 8 langsamer als der std::accmulate Algorithmus. Drastischer fällt der Unterschied für die maximale optimierten Varianten aus. So ist Linux in diesem Fall um den Faktor 15 langsamer, Windows um den Faktor 50.
Zwei Punkte möchte ich noch hervorheben.
- Atomare Datentypen sich um den Faktor 2-3 unter Windows und Linux schneller als ihre Lock Pendanten.
- Insbesondere für atomare Datentype ist Linux um den Faktor 2 schneller als Windows.
Alle Zahlen kompakt
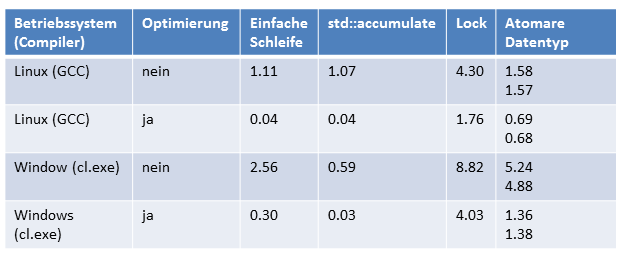
Wer vor lauter Zahlen den Überblick verloren hat. Hier nochmals alle Zeitangaben in Sekunden.
Wie geht's weiter?
Aus Singlethreaded wird Mulithreaded. Im nächsten Artikel wird die Summationsvariable add eine geteilte Variable sein, die von vier Threads verwendet wird. Den synchronisierten Zugriff werde ich durch atomare Datentypen sicherstellen.
 Go to Leanpub/cpplibrary "What every professional C++ programmer should know about the C++ standard library". Hole dir dein E-Book. Unterstütze meinen Blog.
Go to Leanpub/cpplibrary "What every professional C++ programmer should know about the C++ standard library". Hole dir dein E-Book. Unterstütze meinen Blog.






Weiterlesen...