Die Idee ist schnell skizziert. Die Standard Template Library enthält gut 100 Algorithmen für das Suchen, Zählen, Manipulieren von Bereichen und deren Elemente. Mit C++17 wurden 69 der Algorithmen überladen und neue Algorithmen hinzugefügt. Diese überladenen und neuen Algorithmen können mit einer sogenannte Execution Policy aufgerufen werden. Mit dieser Execution Policy lässt sich spezifizieren, ob der Algorithmus sequentiell, parallel oder parallel und vektorisiert ausgeführt wird.
Ein einfaches Beispiel
Vektorisierung bezeichnet die SIMD (Single Instruction, Multiple Data) Erweiterung des Befehlssatzes moderner Prozessoren, die eine Operation parallel auf mehreren Daten ausführen können. Welche überladene Version eines Algorithmus ausgewählt wird, steuert der Anwender über das sogenannte Policy Tag. Wie funktioniert das ganze?
1 2 3 4 5 6 7 8 9 10 11 12 13 |
vector<int> v = ... // standard sequential sort std::sort(v.begin(), v.end()); // sequential execution std::sort(std::parallel::seq, v.begin(), v.end()); // permitting parallel execution std::sort(std::parallel::par, v.begin(), v.end()); // permitting parallel and vectorized execution std::sort(std::parallel::par_unseq, v.begin(), v.end()); |
Schön ist an dem kleinen Beispiel zu sehen, dass die klassische Variante von std::sort (Zeile 4) mit C++17 immer noch zu Verfügung steht. Dagegen lässt sich jetzt mit C++17 explizit die sequentielle (Zeile 7), die parallele (Zeile 10) oder auch die parallele und vektorisierende Variante (Zeile 13) von std::sort anfordern.
Zwei Besonderheiten gilt es aber im Kopf zu behalten.
Zwei Besonderheiten
Zum einen muss ein mit der Exection Policy std::parallel::par_unseq versehener Algorithmus nicht parallel und vektorisiert ausgeführt werden. Zum anderen ist der Anwender für die richtige Anwendung des Algorithmus verantwortlich.
Parallele und vektorisierte Ausführung
Ob ein Algorithmus parallel und vektorisierend (std::parallel::par_unseq) ausgeführt werden kann, hängt von vielen Faktoren ab. Das hängt davon ab, ob die CPU und das Betriebssystem SIMD Anweisungen unterstützt. Natürlich ist es auch eine Frage des Compilers und Optimierungslevels, mit dem der Code übersetzt wird.
1 2 3 4 5 6 7 8 9 10 |
const int SIZE= 8; int vec[]={1,2,3,4,5,6,7,8}; int res[SIZE]={0,}; int main(){ for (int i= 0; i < SIZE; ++i) { res[i]= vec[i]+5; } } |
Die entscheidende Zeile an dem kleinen Programm ist die Zeile 8. Dank dem Compiler Explorer auf https://godbolt.org/ kann ich die Assembleranweisungen des clang 3.6 Compilers mit maximaler (-03) und ohne Optimierung erzeugen.
Ohne Optimierung
Auch wenn ich mich nicht wirklich mit Assembler Instruktionen auskennen, ist unmittelbar klar, hier findet alles sequentiell statt.

Mit maximaler Optimierung
Bei maximaler Optimierung kommen hingegen Instruktionen zum Einsatz, die auf mehreren Elementen gleichzeitig arbeiten.

Sowohl die move-Operationen (movdqa) als auch die add-Operationen (paddd) arbeiten auf den besonderen Registern xmm0 und xmm1. Beide Register sind sogenannte SSE Register und 128 Bits groß. SSE steht für Streaming SIMD Externsions.
Gefahr von kritischen Wettläufen und Verklemmungen
Die Algorithmen schützen nicht automatisch vor kritischen Wettläufen (data races) oder Verklemmungen (deadlocks). Beispiel gefällig?
int numComp= 0; std::vector<int> vec={1,3,8,9,10}; std::sort(std::parallel::vec, vec.begin(), vec.end(), [&numComp](int fir, int sec){ numComp++; return fir < sec; });
Der kleine Programmschnipsel enthält bereits einen kritischen Wettlauf um die Variable numComp.numComp soll die Anzahl der Operationen zählen. Das heißt insbesondere, in der Lambda-Funktion wird auf sie lesend und schreibend zugegriffen. Damit besitzt der Code undefiniertes Verhalten. Um ein wohldefiniertes Programm zu erhalten, muss der Zugriff auf numComp atomar sein.
Statische versus dynamische Execution Policy
Die Execution Policy schaffte es leider nicht in den C++17 Standard. Wir müssen noch bis C++20 warten.
Die Erzeugung eines Threads ist eine teure Operation. Daher macht es keinen Sinn, ein kleinen Container mit einer parallelen (std::parallel::par) oder parallel und vektorisierenden (std::parallel::par_unseq) Strategie zu sortieren. In diesem Fall, frisst der Verwaltungsoverhead den Vorteil der Parallelisierung auf. Noch drastischer können die Nebenwirkungen sein, wenn ein teile und herrsche Algorithmus wie Quicksort zum Einsatz kommt.
1 2 3 4 5 6 7 8 9 10 11 |
template <class ForwardIt> void quicksort(ForwardIt first, ForwardIt last){ if(first == last) return; auto pivot = *std::next(first, std::distance(first,last)/2); ForwardIt middle1 = std::partition(std::parallel::par, first, last, [pivot](const auto& em){ return em < pivot; }); ForwardIt middle2 = std::partition(std::parallel::par, middle1, last, [pivot](const auto& em){ return !(pivot < em); }); quicksort(first, middle1); quicksort(middle2, last); } |
Hier ist die Gefahr natürlich groß, dass die Anzahl der gestarteten Threads deutlich zu groß für das System wird. Umso besser, dass es in C++17 auch eine dynamische Execution Policy gibt.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
std::size_t threshold= ...; // some value template <class ForwardIt> void quicksort(ForwardIt first, ForwardIt last){ if(first == last) return; std::size_t distance= std::distance(first,last); auto pivot = *std::next(first, distance/2); std::parallel::execution_policy exec_pol= std::parallel::par; if ( distance < threshold ) exec_pol= std::parallel_execution::seq; ForwardIt middle1 = std::partition(exec_pol, first, last, [pivot](const auto& em){ return em < pivot; }); ForwardIt middle2 = std::partition(exec_pol, middle1, last, [pivot](const auto& em){ return !(pivot < em); }); quicksort(first, middle1); quicksort(middle2, last); } |
In Zeile 9 und 10 kommt die dynamische Execution Policy zu Einsatz. Per Default wird Quicksort parallel ausgeführt (Zeile 9). Falls aber die Länge des zu sortierenden Bereichs kleiner als eine vorgegebene Schwelle threshold (Zeile 1) ist, wird Quicksort sequentiell ausgeführt (Zeile 10).
Alle Algorithmen
69 der Algorithmen unterstützen eine parallel oder parallele und vektorisierende Ausführung. Hier sind die Kandidaten.
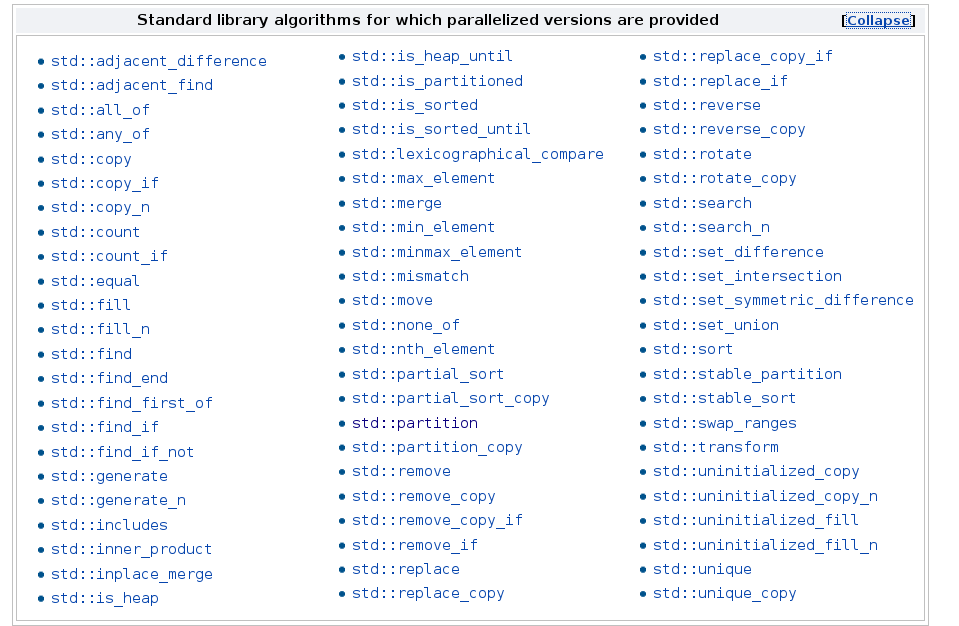
Dazu gibt es 8 neue Algorithmen.
Neue Algorithmen
Die neue Variante des Algorithmus std::for_each und die neuen Algorithmen std::for_each_n, std::exclusive_scan, std::inclusive_scan, std::transfom_exclusive_scan, std::transform_inclusive_scan, std::reduce und std::transform_reduce sind im std Namensraum.
std::for_each std::for_each_n std::exclusive_scan std::inclusive_scan std::transform_exclusive_scan std::transform_inclusive_scan std::reduce std::transform_reduce
Besonders interessant finde ich std::transform_reduce.
Aus transform wird map
Die aus Haskell bekannte Funktion map entspricht der Funktion std::transform in C++. Wenn das kein Wink mit dem Zaunpfahl ist. Denn ersetze ich in den Namen std::transform_reduce transform durch map, so erhalte ich std::map_reduce. MapReduce ist das parallele Framework, das im ersten Schritt jeden Wert auf einen neuen Wert abbildet und im zweiten Schritt diese neuen Werte auf das Ergebnis reduziert.
Dieser zweistufige Algorithmus lässt sich jetzt direkt in C++17 anwenden. Zwar lasse ich meinen Algorithmus jetzt nicht auf einem großen, verteilten System laufen. Doch die Verarbeitungslogik ist dieselbe. So bilde ich in der map Phase in dem Beispiel jedes Wort auf seine Länge ab und summiere die Längen der Worte in der reduce Phase auf. Damit erhalte ich die Gesamtlänge aller Worte eines Vektors.
std::vector<std::string> str{"Only","for","testing","purpose"};
std::size_t result= std::transform_reduce(std::parallel::par,
str.begin(), str.end(),
[](std::string s){ return s.length(); },
0, [](std::size_t a, std::size_t b){ return a + b; });
std::cout << result << std::endl; // 21
Leider konnte ich die parallelen Algorithmen mit keinem Compiler übersetzen. Das werde ich aber nachholen, sobdald ich einen passenden Compiler finde. Daher ist der Code mit Vorsicht zu genießen.
Wie geht's weiter?
Mit dem nächsten Artikel geht es drei Jahre weiter in die Zukunft. In C++20 wird es atomare Smart Pointer geben. In Anlehnung an ihrer C++11 Pendants heißen sie std::atomic_shared_ptr und std::atomic_weak_ptr.
 Go to Leanpub/cpplibrary "What every professional C++ programmer should know about the C++ standard library". Hole dir dein E-Book. Unterstütze meinen Blog.
Go to Leanpub/cpplibrary "What every professional C++ programmer should know about the C++ standard library". Hole dir dein E-Book. Unterstütze meinen Blog.






Weiterlesen...