Vorhersagen über die Zukunft sind schwierig. Insbesondere, wenn sie C++20 betreffen. Trotzdem wage ich ein Blick in die Kristallkugel und werde in den nächsten Artikeln darüber schreiben, auf was wir uns als C++ Entwickler mit C++17 freuen, auf was wir in C++20 hoffen dürfen.
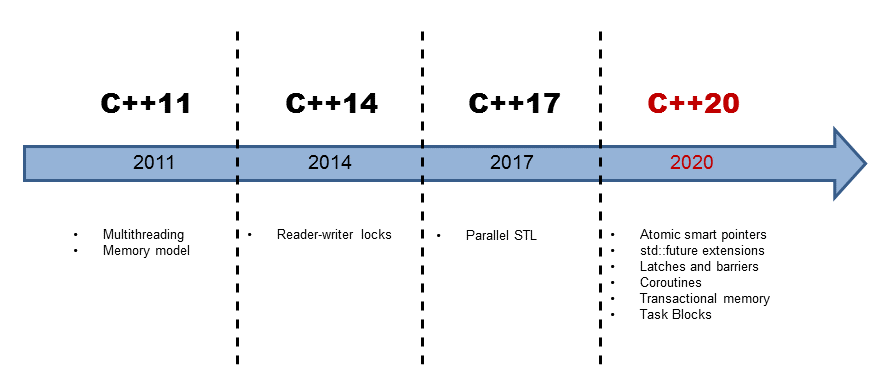
Seit C++11 stellt sich C++ den Anforderungen der Multicore-Architekturen. Der 2011 veröffentlichte Standard definiert, wie sich ein C++ Programm bei mehreren Threads zu verhalten hat. Dabei setzen sich die C++11 Multithreading-Fähigkeiten aus zwei Komponenten zusammen. Das ist zum einen das definierte Speichermodell, das ist zum anderen die standardisierte Threading-Schnittstelle.
Das definierte Speichermodell beschäftigt sich mit Antworten zu den Fragen.
- Was sind atomare Operationen?
- Welche Ordnung von Operationen ist gewährleistet?
- Wann sind Speichereffekte von Operationen sichtbar?
Die standardisierte Threading-Schnittstelle setzt sich auf den folgenden Komponenten zusammen.
- Threads
- Tasks
- Thread-lokale Daten
- Bedingungsvariablen
Für wen das keine alten Hüte sind, den verweise ich gerne auf die Artikel zum C++ Speichermodell und der standardisierten Threading-Schnittstelle.
Mit der Multithreading Brille betrachtet, hat C++14 nicht viel zu C++11 hinzugefügt. C++14 kennt Reader-Writer Locks.
Da stellt sich natürlich die Frage. Was bringt die C++ Zukunft?
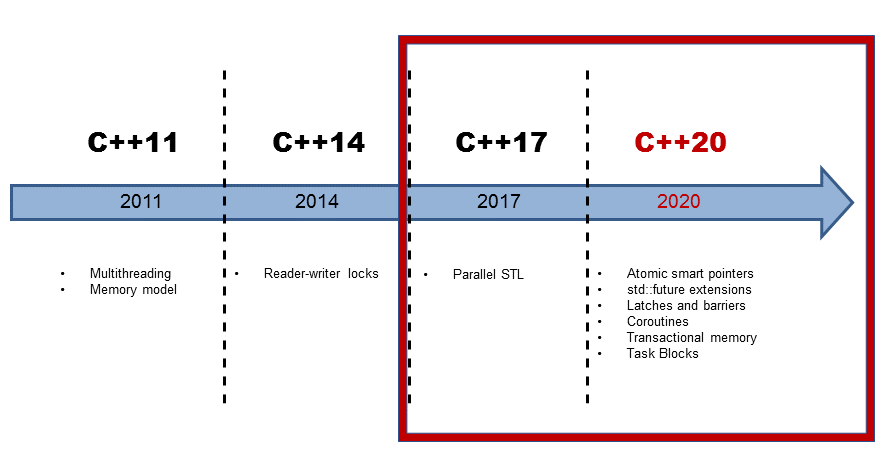
C++17
Mit C++17 wird es parallele Versionen fast aller Algorithmen der Standard Template Library geben. So kann einem Algorithmus die sogenannten execution policy mitgegeben werden. Die execution policy bestimmt, ob der Algorithmus sequentiell (std::seq), parallel (std::par) oder parallel und vektorisierend (std::par_unseq) ausgeführt wird
std::vector<int> vec ={3, 2, 1, 4, 5, 6, 10, 8, 9, 4}; std::sort(vec.begin(), vec.end()); // sequential as ever std::sort(std::execution::seq, vec.begin(), vec.end()); // sequential std::sort(std::execution::par, vec.begin(), vec.end()); // parallel std::sort(std::execution::par_unseq, vec.begin(), vec.end()); // parallel and vectorized
So wird die erste und zweite Variante des sort Algorithmus sequentiell, die dritte parallel und die vierte parallel vektorisierend ausgeführt.
C++20 bietet ganz neue Multithreading Konzepte in C++ an. Diese zeichnen sich im wesentlichen dadurch aus, dass sie Multithreading einfacher und damit weniger fehleranfällig machen.
C++20
Atomare Smart Pointer
Die atomaren Smart Pointer std::shared_ptr und std::weak_ptr besitzen ein konzeptionelles Problem in Multithreading Programmen. Sie teilen ihren veränderlichen Zustand. Damit sind sie natürlich implizit der Gefahr von kritischen Wettläufen und damit von undefiniertem Programmverhalten ausgesetzt. Zwar sichern std::shared_ptr und std::weak_ptr zu, dass das Inkrementieren und Dekrementieren der Referenzzähler eine atomare Operation ist und dass der Destruktor der Ressource genau nur einmal aufgerufen wird, aber sie sichern nicht zu, dass die Zugriffe auf ihre Ressourcen atomar sind. Damit räumen die neuen atomaren Smart Pointer auf.
std::atomic_shared_ptr std::atomic_weak_ptr
Mit Tasks in der Form von Promisen und Futuren führte C++11 ein neues Multithreading Konzept in C++ ein. Trotz ihres großen Mehrwertes besitzen sie eine große Unzulänglichkeit. Futures in C++11 können nicht komponiert werden
std::future Erweiterungen
Mit dieser Unzulänglichkeit räumen Futures in C++20 auf. So wird ein Future genau dann gestartet,
- wenn sein Vorgänger seine Arbeit vollzogen hat:
then:
future<int> f1= async([]() {return 123;}); future<string> f2 = f1.then([](future<int> f) { return f.get().to_string(); });
- wenn einer seiner Vorgänger seine Arbeit vollzogen hat:
when_any:
future<int> futures[] = {async([]() { return intResult(125); }), async([]() { return intResult(456); })}; future<vector<future<int>>> any_f = when_any(begin(futures),end(futures));
- wenn alle seine Vorgänger ihre Arbeiten vollzogen haben:
when_all:
future<int> futures[] = {async([]() { return intResult(125); }), async([]() { return intResult(456); })}; future<vector<future<int>>> all_f = when_all(begin(futures), end(futures));
C++14 kennt keine Semaphoren. Semaphoren erlauben es, dass mehrere Threads gleichzeitig auf eine beschränkte Ressource zugreifen können. Kein Problem, mit C++20 bekommen wir Latches und Barriers.
Latches und Barrieres
Latches und Barriers erlauben es, dass mehrere Threads an einem Synchronisationspunkt warten, bis eine Bedingung erfüllt ist. Dabei ist std::latch für den einmaligen Gebrauch, std::barrier für den mehrmaligen Gebrauch und std::flex_barrier für den mehrmaligen Gebrauch ausgelegt.
1 2 3 4 5 6 7 8 9 10 11 12 |
void doWork(threadpool* pool){ latch completion_latch(NUMBER_TASKS); for (int i = 0; i < NUMBER_TASKS; ++i){ pool->add_task([&]{ // perform the work ... completion_latch.count_down(); }); } // block until all tasks are done completion_latch.wait(); } |
So warten die Threads in Zeile 11, bis completion_latch den Wert 0 besitzt. completion_latch wird in Zeile 2 auf den Wert NUMBER_TASKS gesetzt und in Zeile 7 dekrementiert.
Coroutinen erweitern das Funktionskonzept in C++. Im Gegensatz zu Funktionen können sie ihren Ablauf unterbrechen und wieder aufnehmen und behalten dabei ihren Zustand.
Coroutinen
Coroutinen sind gerne das Mittel der Wahl um kooperatives Multitasking in Betriebssystemen, Ereignisschleifen in Eventsystemen, unendliche Listen oder Pipelines zu implementieren.
1 2 3 4 5 6 7 8 9 10 |
generator<int> getInts(int first, int last){ for (auto i= first; i <= last; ++i){ co_yield i; } } int main(){ for (auto i: getInts(5, 10)){ std::cout << i << " "; // 5 6 7 8 9 10 } |
So gibt die Funktion getInts (Zeile 1 - 5) einen Generator zurück, der auf Anfrage einen neuen Wert erzeugt. Der Ausdruck co_yield erfüllt zwei Aufgaben. Zum einen gibt er den neuen Wert zurück, zum anderen wartet er, bis ein neuer Wert vom Generator angefordert wird. Die Range-basierten for-Schleife in Zeile 8 frägt sukzessive die Werte von 5 - 10 ab.
Mit Transactional Memory wird die bewährte Idee der Transaktion in der Softwareentwicklung angewandt.
Transactional Memory
Transactional Memory basiert auf der Idee der Transaktion aus der Datenbanktheorie. Dabei ist eine Transaktion eine Aktion, die sich durch die Eigenschaften Atomicity, Consistency, Isolation und Durability (ACID) auszeichnet. Bis auf die Durability treffen alle Eigenschafen auch auf Transactional Memory zu. C++ kennt Transactional Memory in zwei Formen. So kennt C++ Synchronized Blocks und Atomic Blocks. Gemein ist beiden, das sie in einer einzigen, totalen Ordnung ausgeführt werden und sie sich verhalten, wie wenn sie durch ein globales Lock geschützt werden. Während in Synchronized Block transaction-unsafe Code ausgeführt werden kann, ist dies in einem Atomic Block nicht erlaubt.
So kann std::cout zwar in einem Synchronized Block ausgeführt werden aber nicht in einem Atomic Block.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
int func() { static int i = 0; synchronized{ std::cout << "Not interleaved \n"; ++i; return i; } } int main(){ std::vector<std::thread> v(10); for(auto& t: v) t = std::thread([]{ for(int n = 0; n < 10; ++n) func(); }); } |
Der synchronized Schlüsselwort in Zeile 3 sichert zu, dass sich die Ausführung der Synchronized Blocks (Zeile 3 - 7) nicht überlagern. Das heißt insbesondere, dass es eine einzige, globale Ordnung zwischen allen Synchronized Blöcken gibt. Nochmals anders ausgedrückt. Das Ende jedes Synchronized Blocks synchronisiert sich mit dem Anfang des nächsten Synchronized Block.
Auch wenn ich den Artikel Multithreading in C++17 und C++20 genannt habe, so gibt es neben der parallelen STL noch ein weiteres Feature, dass das einfache parallelisieren von Aufgaben erlaubt.
Task Blocks
Task Blocks setzen das Fork-Join Paradigma um. Die Graphik bringt dies einfach auf den Punkt.
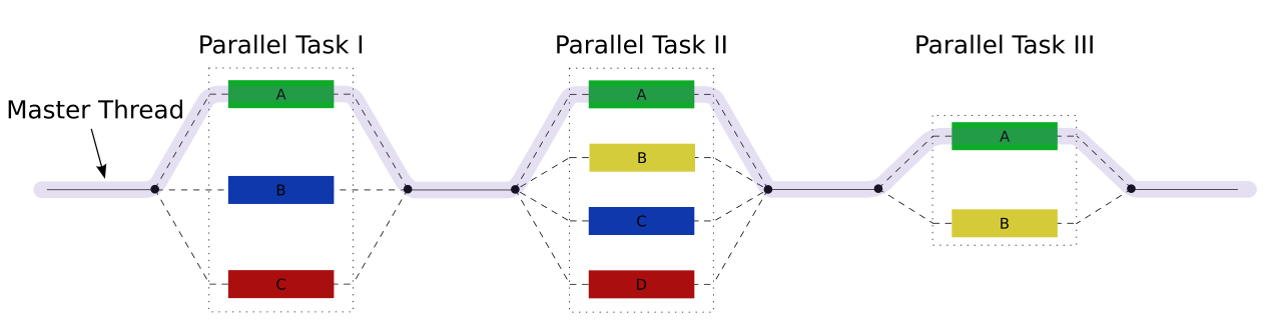
In einem Task Block können durch den run Aufruf neue Task geforked werden, die am Ende des Task Blocks wieder gejoined werden.
1 2 3 4 5 6 7 8 9 10 11 |
template <typename Func> int traverse(node& n, Func && f){ int left = 0, right = 0; define_task_block( [&](task_block& tb){ if (n.left) tb.run([&]{ left = traverse(*n.left, f); }); if (n.right) tb.run([&]{ right = traverse(*n.right, f); }); } ); return f(n) + left + right; } |
traverse ist eine Funktions Template, das auf jedem Knoten des Baumes node mit zwei Kindern die Funktion Func aufruft. Das Schlüsselwort define_task_block definiert den Task Block. In diesem kann der Task Block tb neue Tasks starten. Genau das findet für den linken und rechten Zweig des Baumes in Zeile 6 und 7 statt. Zeile 9 ist das Ende des Task Blocks und damit der Synchronisationspunkt.
Wie geht's weiter?
Nachdem dem Überblick zu den neuen Featuren rund um Multithreading in C++17 und C++20 folgen in den nächsten Artikeln die Details. Los geht es mit der parallelen STL. Dabei bin ich mir ziemlich sicher. Dieser Artikel hat mehr Fragen unbeantwortet gelassen als beantwortet.
 Go to Leanpub/cpplibrary "What every professional C++ programmer should know about the C++ standard library". Hole dir dein E-Book. Unterstütze meinen Blog.
Go to Leanpub/cpplibrary "What every professional C++ programmer should know about the C++ standard library". Hole dir dein E-Book. Unterstütze meinen Blog.






Weiterlesen...