Die atomaren Datentypen sind die Grundlage für das C++-Speichermodell. Per Default gilt für sie die sequenzielle Konsistenz.
Das starke C++-Speichermodell
In 2004 erhielt Java 5.0 sein aktuelles Speichermodell, in 2011 C++. Davor besaß Java ein fehlerhaftes, C++ gar kein Speichermodell. Wer nun glaubt, dass dies der Endpunkt eines langen Reifungsprozesses ist, der irrt sich. Tatsächlich wurden die Grundlagen für die Multithreading Programmierung bereits vor 40 bis 50 Jahren gelegt. So definierte Leslie Lamport 1979 das Konzept der sequenziellen Konsistenz.
Die sequenzielle Konsistenz sichert zwei Eigenschaften zu.
- Die Anweisungen eines Programms werden in der Sourcecodereihenfolge ausgeführt.
- Es gibt eine globale Reihenfolge aller Operationen auf allen Threads.
Bevor ich die zwei Eigenschaften genauer analysiere, will ich explizit darauf hinweisen. Diese Aussagen gelten nur für atomare Datentypen, besitzen aber Auswirkungen auf nichtatomare Datentypen.
Die einfache Graphik symbolisiert zwei Threads, die jeweils den Wert 1 in einer Variable x bzw. y speichern, diese Variablen wieder laden und in den Variablen res1 bzw. res2 speichern.
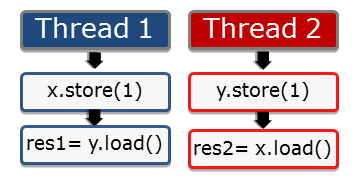
Die Operationen finden auf atomaren Datentypen statt und sind daher implizit atomar. Per Default gilt die sequenzielle Konsistenz. In welcher Reihenfolge können die Anweisungen nun ausgeführt werden?
Eigenschaft 1 der sequenziellen Konsistenz sichert zu, dass die Befehle in der Reihenfolge ausgeführt werden, in der sie im Sourcecode stehen. Damit ist klar. Keine Speicher-Operatione (store) kann eine Lade-Operation (load) überholen.
Eigenschaft 2 der sequenziellen Konsistenz sichert zu, dass es eine globale Reihenfolge aller Operationen auf allen Threads gibt. Das heißt in dem konkreten Fall, dass der Thread 2 die Operationen auf dem Thread 1 in der gleichen Reihenfolge wahrnimmt, wie sie der Thread 1 ausführt. Damit sieht Thread 2 alle Operationen des Thread 1 in der Sourcecodereihenfolge des Thread 1. Die gleiche Argumentation gilt natürlich auch aus der Sicht von Thread 1. Eigenschaft 2 lässt sich am einfachsten als globaler Zeittakt verstehen, dem alle Threads zu folgen haben. Dieser globale Zeittakt ist die globale Reihenfolge.
Nun ist das Rätsel fast schon gelöst. Was noch übrig bleibt, ist es, alle zulässigen Verschränkungen der zwei Threads zu betrachten. Damit sind die sechs folgenen Ausführungsreihenfolgen der zwei Threads möglich.
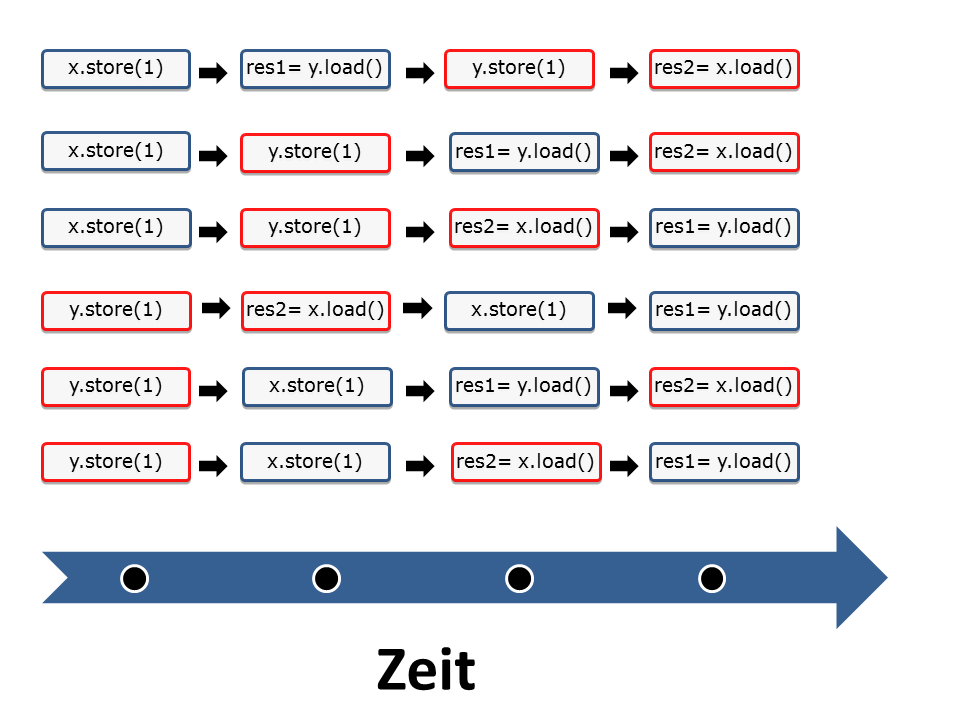
Das war einfach. Oder?
Vom starken zum schwachen C++-Speichermodell
Gerne wil ich auf das Bild des Vertrages zwischen dem Programmierer und dem System zurückkommen.
Der Programmierer verwendet in diesem konkreten Beispiell atomare Variablen. Sein Teil des Vertrages erfüllt er, indem er sie richtig anwendet. Da System sichert ihm ein definiertes Programmverhalten ohne kritischen Wettlauf zu. Darüber hinaus kann das System die vier Operationen in sechs verschiedenen Kombinationen ausführen. Wählt der Programmier anstelle der Sequenziellen Konsistenz die Relaxed Semantik, so verändern sich deutlich die Rahmenbedingungen für den Vertrag. Zum einen ist es deutlich schwieriger für den Programmierer, den Vertrag richtig zu anzuwenden, zum anderen stehen dem System deutlich mehrere Optimierungsmöglichkeiten offen. Mit der Relaxed Semantik oder auch dem schwachen C++-Speichermodell sind viel mehr Operationenreihenfolgen der 4 Operationen zulässig. Das verwirrend ist, dass der Thread 1 die vier Operationen in einer anderen Reihenfolge sehen kann als der Thread 2. Wir müssen uns in unserer Intuition vom globalen Zeittakt lösen. So kann der Thread 1 seine Anweisungen in Sourcecodeorder ausführen, aus Sicht von Thread 2 ist es aber möglich, dass die Operation res1= y.load() die Operation x.store() überholt.
Zwischen der sequenziellen Konsistenz oder auch dem starken C++-Speichermodell und der relaxed Semantik gibt es noch einige Abstufungen. Am wichtigsten ist die Acquire-Release-Semantik. Sie werden es sicher schon ahnen. Mit der Acquire-Release-Semantik hat der Programmierer strengere Regeln einzuhalten als mit der sequenziellen Konsistenz, dem System stehen dafür aber auch mehr Optimierungsmöglichkeiten offen. Die Acquire-Release-Semantik ist der Schlüssel zum tieferen Verständnis der Multithreading Programmierens, denn durch die Acquire-Release Semantik werden Threads an definierten Stellen miteinander synchronisiert. Ohne diese Synchronisation ist kein definiertes Verhalten von Threads, Task oder Bedingungsvariablen möglich. Dazu aber in einem späteren Artikel mehr.
Wie geht's weiter?
Im nächsten Artikel werde ich tiefer auf atomare Datentypen in C++ eingehen. Damit bleiben wir beim starken C++-Speichermodell.
 Go to Leanpub/cpplibrary "What every professional C++ programmer should know about the C++ standard library". Hole dir dein E-Book. Unterstütze meinen Blog.
Go to Leanpub/cpplibrary "What every professional C++ programmer should know about the C++ standard library". Hole dir dein E-Book. Unterstütze meinen Blog.






Weiterlesen...