Seit dem C++11-Standard besitzt C++ ein Speichermodell. Dieses Speichermodell ist die elementare Grundlage dafür, das C++ Programme in Multithreading Umgebungen ein definiertes Verhalten haben.
Das C++-Speichermodell kennt zwei Aspekte für den Programmierer. Auf der einen Seite steht die Pflicht, sich mit der hohen Komplexität des Speichermodells, das oft der Intuition widerspricht, auseinanderzusetzen, auf der anderen Seite steht die Kür, einen viel tieferen Einblick in die Komplexität von Multithreading Programmen zu erreichen.
Der Vertrag
In der ersten Annäherung beschreibt das C++-Speichermodell einen Vertrag. Dieser Vertrag besteht zwischem dem Programmierer und dem System. Zum einen fordert der Vertrag von dem Programmierer, bestimmte Regeln genau einzuhalten, zum anderen bietet es dem System alle Freiheiten, solange das System die Regeln einhält. Als Ergebnis resultiert im Idealfall ein definiertes ausführbares Programm, das im Rahmen der Regeln maximal optimiert ist. Genau genommen ist es kein einziger Vertrag, sondern eine sehr feingranular anpassbare Abstufung von Verträgen. Das heißt, je lockerer die Regeln sind, die der Programmierer einzuhalten hat, desto mehr Möglichkeiten besitzt das System, optimierte ausführbare Programme zu erzeugen.
Der Faustregel ist ganz einfach. Je strenger der Vertrag ist, desto weniger Freiheiten hat das System, optimierte ausführbare Dateien zu erzeugen. Der Umkehrschluß geht leider nach hinten los. Eine sehr lockere Abstufung des Vertrages oder des C++-Speichermodells zu wählen, besitzt zwar hohes Optimierungspotential. Leider sind solche Programme nur noch von wenigen ausgewiesenen Experten zu zügeln.
Die Graphik stellt die Abstufungen des Vertrages dar. Auch wenn diese starke Vereinfachung hinkt, schärft sie den Blick fürs Wesentliche.
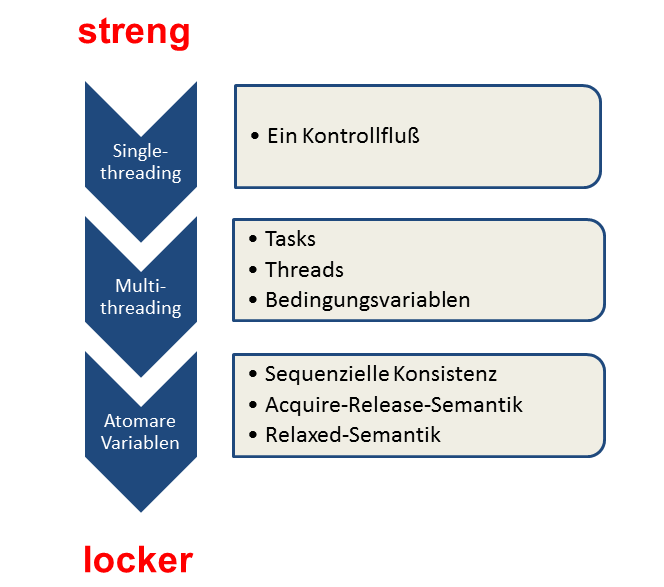
Es gibt drei Abstufungen des Vertrags in C++11.
Bis zum C++11-Standard gab es nur einen Vertrag. C++ war sich der Existenz von Multithreading Progammen oder atomaren Variablen nicht bewußt. Das System kannte nur einen Kontrollfluß und besaß damit auch relativ wenig Freiheiten, das ausführbare Programm zu optimieren. Im Wesentlichen musste das System für den Programmierer die Illusion aufrechterhalten, dass das beobachte Programmverhalten der Reihenfolge der Sourcecodebefehle entsprach. Natürlich gab es zu diesem Zeitpunkt noch kein Speichermodell. C++ kannte Sequence Points. Sequence Points sind Positionen im Programm, an denen alle Aktion davor sichtbar sein müssen. Der Beginn der Ausführung einer Funktion oder deren Verlassen sind klassische Sequence Points. Wird hingegen eine Funktion mit zwei Argumenten add(a++,a) aufgerufen, ist es nicht im C++ Standard spezifiziert, welches Argument als erstes ausgewertet wird. Daher ist das Verhalten undefiniert. Der Grund ist ganz einfach, das Kommazeichen ist kein Sequence Point. Das ändert sich auch nicht mit C++11.
Mit C++11 ändert sich alles. C++11 ist sich zum ersten Mal der Existenz mehrerer Threads bewußt. Die Grundlage des definierten Verhaltens mehrerer Threads ist das C++-Speichermodell. Dies ist an das Java-Speichermodell angelehnt, geht aber in typischer C++-Manier noch ein paar Schritte weiter. Dazu mehr in den nächsten Artikeln. Nun gilt es für den Programmierer einige Regeln im Umgang mit geteilten Variablen zu beachten, damit das Programmverhalten definiert ist. Undefiniert ist das Programmverhalten, wenn es zumindestens einen kritischen Wettlauf besitzt. Kritische Wettlauf laueren gerne dann, wenn Threads Daten teilen. Daher sind Tasks deutlich leichter richtig zu verwenden als Threads oder gar Bedingungsvariablen.
Mit den atomaren Variablen betreten wir einen Bereich, der nur von Experten zu meistern ist. Das gilt umso mehr, je weiter das C++-Speichermodell abgeschwächt wird. Gerne wird der Umgang mit atomaren Variablen als auch lockfreie Programmierung bezeichnet. Ich habe im Laufe des Artikels habe ich gerne von lockeren und strengen Regeln gesprochen. Tatsächlich wird die Sequenzielle Konsistenz als Strong Memory Model, die Relaxed Semanik als Weak Memory Model bezeichnet.
Der Vertragsinhalt
Der Vertrag zwischen dem Programmierer und dem System setzt sich aus drei Komponenten zusammen.
- Atomare Operationen: Operationen, die eine Anwendung ohne Unterbrechung ausgeführt muss
- Partielle Ordnung von Operationen: Reihenfolge von Operationen, die nicht umsortiert werden können
- Speichersichtbarkeit: Zusicherung, ab oder bis wann Operationen auf gemeinsam genutzen Variablen für einen anderen Thread sichtbar sind
Grundlage des Vertrages oder auch der C++-Speichermodells sind atomare Datentypen. Diese zeichnen sich durch zwei Eigenschafen aus. Zum einen sind sie - wie unschwer zu erraten - atomar, zum anderen setzen sie Synchronisations- und Ordnungsbedingungen an die Programmausführung. Dies Synchronisations- und Ordungsbedingungen geltern auch für nichtatomare Datentypen. Während ein atomarer Datentyp immer atomar bleibt, erlaubt das C++-Speichermodell, die Synchronisations- und Ordnungsbedingungen feingranular anzupassen.
Wie geht's weiter?
In den nächsten Artikeln werde ich deutlich weiter in die Untiefen des C++-Speichermodells abtauchen. Das heißt insbesondere, dass die nächsten Artikel die lockfreien Programmierung zum Thema haben. Auf meiner Tour werde ich atomare Datentypen und Operationen auf ihnen vorstellen. Sind diese Grundlagen gelegt geht, gehe ich weiter auf die verschiedenen Abstufungen des C++-Speichermodells ein. Starten werde ich mit der relativ intuitiven sequenziellen Konsistenz, fortfahren mit der schon deutlich anspruchsvolleren Acquire-Release Semantik und enden mit der sehr unintuitiven Relaxed-Semanik. Los geht es im nächsten Artikel mit der Sequenzielle Konsistenz. Die sequenzielle Konsistenz stellt das Standardverhalten für atomare Datentypen dar.
Hintergrundinformation
- System
- Vereinfachend gesprochen, verstehe ich unter dem System die drei Komponenten Compiler, Prozessor und die diversen Speicherhierachien. Der Compiler übersetzt das Programm in Assembleranweisungen, der Prozessor führt die aus und die diversen Speicherhierachien repräsentieren den Zustand des ausgeführten Progamms.
- sequence point
- Die Details zu sequence points lassen sich auf Wikipedia nachlesen.
- Lockfreie Programmierung
- Umgangssprachlich wird lockfreies Programmierung als Programmieren ohne Mutexe bezeichnet. Diese Definition ist aber zu eng gefasst. Ein Codeabschnitt ist lockfrei, wenn sich keine Prozesse bzw. Threads gegenseitig blockieren können.
- C++-Speichermodell
- Ein relativ einfachen Einstieg in das Speichermodell bietet der Artikel Der Vertrag 06/2014.
-
 Go to Leanpub/cpplibrary "What every professional C++ programmer should know about the C++ standard library". Hole dir dein E-Book. Unterstütze meinen Blog.
Go to Leanpub/cpplibrary "What every professional C++ programmer should know about the C++ standard library". Hole dir dein E-Book. Unterstütze meinen Blog.






Weiterlesen...