Mit der Acquire-Release-Semantik verlassen wir das Default-Speichermodell in C++. In der Acquire-Release-Semantik findet die Synchronisation nicht zwischen Threads, sondern zwischen atomaren Operationen auf der gleichen atomaren Variable statt.
Acquire-Release-Semantik
Da in der Acquire-Release-Semantik nicht mehr die Threads, sondern nur noch atomare Operationen synchronisiert werden, ist die Acquire-Release-Semantik schwächer und daher leichtgewichtiger und performanter als die sequenzielle Konsistenz. Leider steigt auch deutlich der intellektuelle Anspruch.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
#include <atomic> #include <iostream> #include <thread> std::atomic<int> x{0}; std::atomic<int> y{0}; void writing(){ x.store(2000,std::memory_order_relaxed); y.store(11,std::memory_order_release); } void reading(){ std::cout << y.load(std::memory_order_acquire) << " "; std::cout << x.load(std::memory_order_relaxed) << std::endl; } int main(){ std::thread thread1(writing); std::thread thread2(reading); thread1.join(); thread2.join(); }; |
Beim ersten Blick fällt auf, das alle Operationen atomar sind. Damit ist das Programm wohldefiniert. Der zweite Blick offenbart deutlich mehr. So sind die atomaren Operationen auf y mit der dem Flag std::memory_order_release (Zeile 10) und std::memory_order_acquire (Zeile 14) annotiert. Im Gegensatz dazu folgen alle Operationen auf x der Relaxed-Semantik. Damit lassen sich keine Synchronisations- und Ordnungsbedingungen von x ableiten. Der Schlüssel zu der Antwort, welche Werte für x und y möglich sind, kann nur durch y beantwortet werden.
Es gilt:
- y.store(11,std::memory_order_release) synchronizes-with y.load(std::memory_order_acquire)
- x.store(2000,std::memory_order_relaxed ist sichtbar vor y.store(11,std::memory_order_release)
- y.load(std::memory_order_acquire) ist sichbar vor x.load(std::memory_order_relaxed)
Diese drei Aussagen werde ich gerne nochmals in mehr Prosa beschreiben. Die zentrale Idee ist es, dass das Speichern von y in Zeile 10 mit dem Laden von y in Zeile 14 synchronisiert. Der Grund ist, dass die Operationen auf der gleichen atomaren Variable y stattfinden, die mit der Acquire-Release-Semantik durch std::memory_order_release (Zeile 10) bzw. std::memory_order_acquire(Zeile 14) versehen sind. Diese paarweise Operation auf y besitzt noch ein weitere sehr interessante Eigenschaft. Sie stellt in jeweils eine Richtung von y aus gesehen für die Variable x eine Art Barriere dar. So kann das x.store(2000,std::memory_order_relaxed) nicht nach dem y.store(std::memory_order_release), so kann das x.load() nicht vor dem y.load() ausgeführt werden.
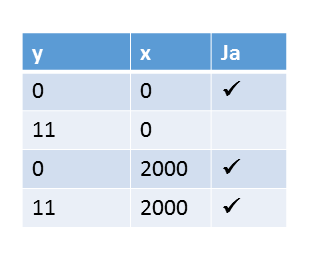
Die Argumentation war im Fall der Acquire-Release-Semantik deutlich anspruchsvoller als die im Fall der sequenziellen Konsistenz. Die zulässigen Werte für x und y sind aber die gleichen. Entsprechend ist die Wertkombination y == 11 und x == 0 nicht zulässig.
Damit sind auch vier verschränkte Ausführungen der Threads möglich, die drei verschiedene Ausgabekombinationen erzeugen können.
- thread1 wird vollständig vor thread2 ausgeführt.
- thread2 wird vollständig vor thread1 ausgeführt.
- thread1 führt nur die erste Operation x.store(2000) aus, bevor thread2 ausgeführt wird.
Zum Abschluß noch die Tabelle.
Überoptimiert
Ein typischer Denkfehler bei der Acquire-Release-Semantik ist es, anzunehmen, dass die acquire-Operation (Zeile 14) auf die release-Operation (Zeile 10) wartet. Das gilt natürlich nicht. Es gilt nur: Wenn die y.store(11,std::memory_order_release)-Operation vor der y.load(std::memory_order_acquire)-Operation stattgefunden hat, dann sind alle Operationen vor der store-Operation (Zeile 10) zum Zeitpunkt der load-Operation (Zeile 14) sichtbar.
Wer nun fälschlich annimmt, dass die acquire-Operation auf die release-Operation wartet, kommt zwangsläufig auf die Idee, das y keine atomare Variable sein muss. Damit lässt sich das Programm weiter optimieren.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
#include <atomic> #include <iostream> #include <thread> int x{0}; std::atomic<int> y{0}; void writing(){ x= 2000; y.store(11,std::memory_order_release); } void reading(){ std::cout << y.load(std::memory_order_acquire) << " "; std::cout << x << std::endl; } int main(){ std::thread thread1(writing); std::thread thread2(reading); thread1.join(); thread2.join(); }; |
Das Programm besitzt einen kritischen Wettlauf um die Variable x und ist damit undefiniert. Warum? Wenn y.store(11,std::memory_order_release) (Zeile 10) vor y.load(std::memory_order_acquire) (Zeile 14) ausgeführt wird, ist zugesichert, dass x= 2000 (Zeile 9) vor dem Lesen von x in Zeile 15 ausgeführt wird. Wenn aber nicht. Dann wird x= 2000 gleichzeitig mit dem Lesen von x ausgeführt. Bei der verschränkten Ausführung der zwei Threads (Fall 3 in Ausgabekombinationen) kommt es zu einem gleichzeitigen Zugriff auf die Variable x, wobei der Thread thread1 versucht, diese zu modifizieren.
Die Tabelle bringt es auf Punkt.
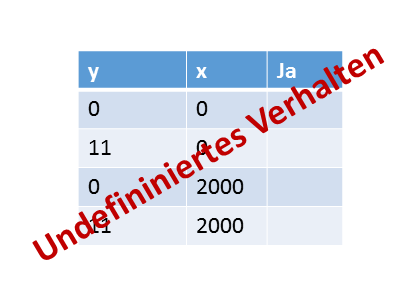
Dieser Lapsus ist mir in meiner Präsentation "Mulithreading done right?" in Berlin unterlaufen. In Moskau habe ich aber schon dazugelernt. Ich habe nie behauptet, dass das C++-Speichermodell einfach zu verdauen ist.
Wie geht's weiter?
Schwächer als die Acquire-Release-Semantik ist nur die Relaxed-Semantik. Im nächsten Artikel werden wir diese für die atomaren Operationen einsetzen.
 Go to Leanpub/cpplibrary "What every professional C++ programmer should know about the C++ standard library". Hole dir dein E-Book. Unterstütze meinen Blog.
Go to Leanpub/cpplibrary "What every professional C++ programmer should know about the C++ standard library". Hole dir dein E-Book. Unterstütze meinen Blog.






Weiterlesen...