Dieser Artikel beendet meine Miniserie über CppMem. Heute breche ich die Sequenzielle Konsistenz und tauche damit tief ein in die Expertendomäne.
Grundlage meiner Analyse ist das Programm aus dem Artikel Sukzessive Optimierung. Wer den Weg bisher besser verstehen will, verweise ich gerne auf alle bisherigen Artikel zu CppMem. Los geht es mit der Acquire-Release-Semantik.
Acquire-Release-Semantik
Zuerst zu dem Programm, dass ich in CppMem ausführe.
int main(){
atomic_int x= 0;
atomic_int y= 0;
{{{ {
x.store(2000,memory_order_relaxed);
y.store(11,memory_order_release);
}
||| {
y.load(memory_order_acquire);
x.load(memory_order_relaxed);
}
}}}
}
Aus dem Artikel Sukzessive Optimierung - Acquire-Release-Semantik wissen wir bereits, alle Ergebnisse außer (y=11, x=0) sind möglich.
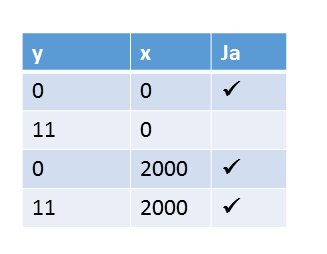
Mögliche Programmausführungen
Schauen wir uns doch die Graphen der drei konsistenten Ausführungen dazu an. Schön zeigen die Graphen, dass die Acquire-Release-Semantik zwischen dem Schreiben von y als Release-Operation und dem Lesen von y als Acquire-Operation besteht. Dabei ist es unerheblich, ob das Lesen von y im main-Thread (y=0) oder im separaten Thread (y=11) stattfindet. In den Graphen ist die Acquire-Release-Semantik durch sw (synchronizes-with) annotiert.
Ausführung für (y=0, x= 0)
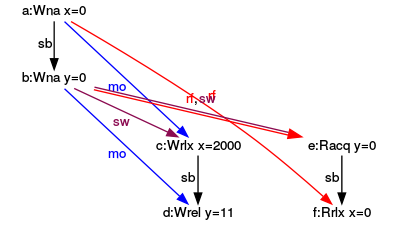
Ausführung für (y= 0, x= 2000)
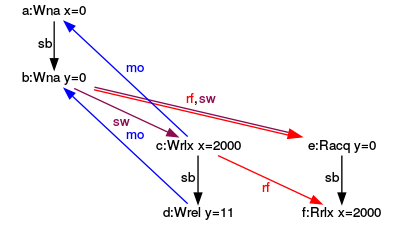
Ausführung für (y=11, x= 2000)

Wird aus der atomaren Variable x, deren Operationen der Relaxed-Semantik folgen, eine nicht atomare Variable, bringt dies CppMem sofort auf den Punkt.
Überoptimiert
int main(){ int x= 0; atomic_int y= 0; {{{ { x= 2000; y.store(11,memory_order_release); } ||| { y.load(memory_order_acquire); x; } }}} }
Der kritische Wettlauf tritt genau dann auf, wenn der erste Thread x=2000 schreibt, und der lesende Thread die Variable x liest. Das zeigt der entsprechende Graph durch ein dr (data race) an.
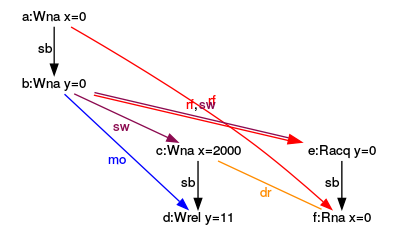
Welche Ergebnisse sind möglich, wenn alle atomaren Operationen auf der Relaxed-Semantik basieren?
Relaxed-Semantik
int main(){
atomic_int x= 0;
atomic_int y= 0;
{{{ {
x.store(2000, memory_order_relaxed);
y.store(11,memory_order_relaxed);
}
||| {
y.load(memory_order_relaxed);
x.load(memory_order_relaxed);
}
}}}
}
Die Relaxed-Semantik sichert keine Synchronisations- und Ordnungsbedingungen zu. Damit sind alle Ergebnisse für y und x möglich.

Aus Sicht des lesenden Threads können die Operationen im schreibenden Thread in einer anderen Reihenfolge als seiner Sourcecodereihenfolge stattfinden. Wie schaut der Graph für das Ergebnis (y=0, x=2000) aus?
Ausführung (y=0,x=2000)
Der Graph bringt das unintuitives Verhalten direkt auf den Punkt.
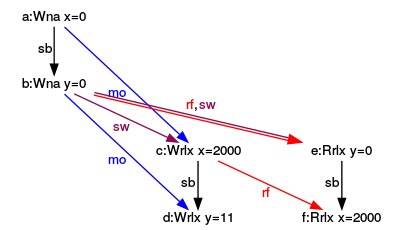
x liest den Wert 2000 von dem schreibenden Thread, während y den Wert 0 vom main-Thread liest. Dies gilt, obwohl im lesenden Thread das Lesen von y vor dem Lesen von x stattfindet. Vor bedeutet in diesem Fall, dass die Operation e:Rrix sb (sequenced-before) der Operation f:Rrix ist.
Wie geht's weiter
Meine Vorstellungen zum C++-Speichermodell auf der Parallel 2016, der ADC++ und der Münchner C++-Usergruppe habe ich bereits gehalten, bzw. stehen in ein paar Tagen an. Daher werde ich mich mit diesem Artikel das C++-Speichermodell wieder verlassen und mich wieder der Embedded Programmierung mit C++ zuwenden. Ein großer Themenblock der Embedded Programmierung steht noch aus. Der sorgfältige Umgang mit Ressourcen.
 Go to Leanpub/cpplibrary "What every professional C++ programmer should know about the C++ standard library". Hole dir dein E-Book. Unterstütze meinen Blog.
Go to Leanpub/cpplibrary "What every professional C++ programmer should know about the C++ standard library". Hole dir dein E-Book. Unterstütze meinen Blog.






Weiterlesen...