Singletons lassen sich in vielen Variationen in C++11 threadsicher initialisieren. Dabei können vereinfachend gesprochen Zusicherung der C++-Laufzeit, Locks oder auch atomare Operationen verwendet werden. Mich interessiert vor allem in diesem Artikel die Antwort auf die Frage: Welche Performanzunterschiede bestehen zwischen den Variationen?
Meine Strategie
Als Referenzwert verwende ich ein Singleton Objekt, auf dass ich 40 Millionen Mal zugreife. Der erste Zugriff initialisiert das Objekt. Im Gegensatz dazu werden die Zugriffe aus dem Multithreading Programm von 4 Threads aus stattfinden. Hier gilt mein Interesse nur der reinen Performanz der Zugriffe. Die Programme lasse ich auf zwei physikalischen Rechner laufen. Unter Linux besitzt mein Rechner vier, unter Windows aber nur zwei Kerne. Beide Programme übersetze ich sowohl ohne als auch mit maximaler Optimierung. Bei der Übersetzung mit maximaler Optimierung muss ich einen kleinen Trick anwenden, indem ich eine volatile Variable dummy in der statischen Methode getInstance verwende. Dies hat den einfachen Grund, dass dadurch der Optimierer den Zugriff auf das Singleton Objekt nicht wegoptimieren darf.
Drei Fragestellung stehen jetzt im Vordergrund:
- Wie ist die relative Performanz der verschiedenen Singleton Implementierungen?
- Gibt es signifikate Unterschiede in der relativen Performanz zwischen Linux (gcc) und Windows (cl.exe)?
- Welche Unterschiede bestehen zwischen der optimierten und nicht optimierten Programmen?
Zum Abschluss werde ich die nackten Zahlen in einer Tabelle zusammenfassen. Alle Zahlenangaben sind in Sekunden.
Die Referenzwerte
Die verwendeten Compiler
Die Details zu den Compiler lassen sich am besten direkt von der Kommandozeile auslesen.
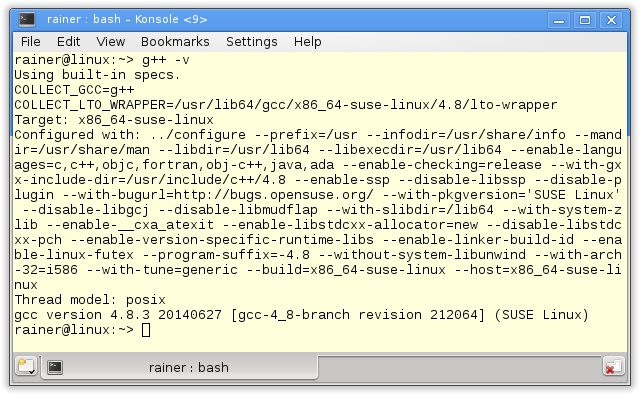

Der Referenzcode
Der Zugriff auf das nicht synchronisierte Singleton Objekt.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
// singletonSingleThreaded.cpp #include <chrono> #include <iostream> constexpr auto tenMill= 10000000; class MySingleton{ public: static MySingleton& getInstance(){ static MySingleton instance; // volatile int dummy{}; return instance; } private: MySingleton()= default; ~MySingleton()= default; MySingleton(const MySingleton&)= delete; MySingleton& operator=(const MySingleton&)= delete; }; int main(){ constexpr auto fourtyMill= 4* tenMill; auto begin= std::chrono::system_clock::now(); for ( size_t i= 0; i <= fourtyMill; ++i){ MySingleton::getInstance(); } auto end= std::chrono::system_clock::now() - begin; std::cout << std::chrono::duration<double>(end).count() << std::endl; } |
In der Referenzimplementierung verwende ich das sogenannte Meyers Singleton. Das elegante an dieser Implementierung ist, dass die Singleton Objekt in Zeile 11 als statische Variablen mit Blockgültigkeit genau dann initialisiert wird, wenn die statische Methode getInstance (Zeile 10 - 14) das erste Mal aufgerufen wird. In Zeile 14 ist die volatile Variable dummy auskommentiert. Diese Zeile verwende ich dann, wenn ich das Programm mit maximaler Optimierung übersetze. Dadurch verhindere ich, dass in diesem Fall der Aufruf der MySingleton::geInstance() Methode wegoptimiert wird.
Nun die nackten Zahlen unter Linux und Windows.
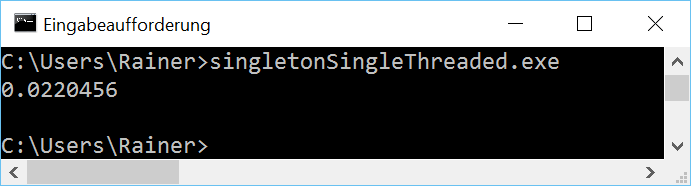
Ohne Optimierung


Maximale Optimierung

Zusicherungen der C++-Laufzeit
Die Details zur threadsicheren Initialisierung von Variablen habe ich in dem Artikel Sicheres Initialisieren der Daten vorgestellt.
Meyers Singleton
Das Schöne am Meyers Singleton im C++11-Standard ist es, dass deren Umsetzung automatisch threadsicher ist, denn diese wichtige Eingschaft sichert der Standard für statische Variablen mit Blockgültigkeit zu. Das Meyers Singleton ist eine statische Variable mit Blockgültigkeit. Damit muss ich das Programm nur noch für vier Threads umschreiben.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
// singletonMeyers.cpp #include <chrono> #include <iostream> #include <future> constexpr auto tenMill= 10000000; class MySingleton{ public: static MySingleton& getInstance(){ static MySingleton instance; // volatile int dummy{}; return instance; } private: MySingleton()= default; ~MySingleton()= default; MySingleton(const MySingleton&)= delete; MySingleton& operator=(const MySingleton&)= delete; }; std::chrono::duration<double> getTime(){ auto begin= std::chrono::system_clock::now(); for ( size_t i= 0; i <= tenMill; ++i){ MySingleton::getInstance(); } return std::chrono::system_clock::now() - begin; }; int main(){ auto fut1= std::async(std::launch::async,getTime); auto fut2= std::async(std::launch::async,getTime); auto fut3= std::async(std::launch::async,getTime); auto fut4= std::async(std::launch::async,getTime); auto total= fut1.get() + fut2.get() + fut3.get() + fut4.get(); std::cout << total.count() << std::endl; } |
Die Singleton Objekte verwende ich in der Funktion getTime in Zeile 24 - 32. Die Funktion wird von den vier Promisen in den Zeilen 36 - 39 ausgeführt. Die assozierten Future sammeln alle Ergebnisse in der Zeile 41 ein. Jetzt fehlt nur noch die Ausführungszeiten des Programms in Sekunden.
Ohne Optimierung
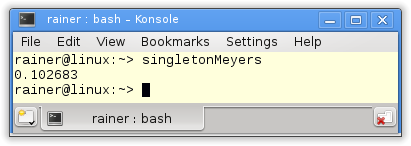
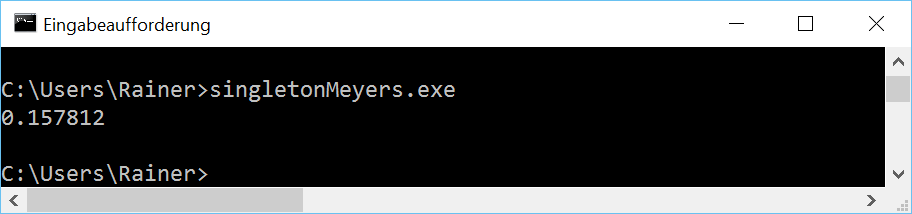
Maximale Optimierung


Weiter geht's mit der der Funktion std::call_once in Kombination mit dem Flag std::once_flag.
Die Funktion std::call_once und das std::once_flag
Mit der Funktion std::call_once lässt sich eine aufrufbare Einheit registrieren, die mit Hilfe des std::once_flag genau einmal ausgeführt wird. In der nächsten Variation des Singleton Patterns stellt die Funktion std::call_once sicher, dass das Singleton Objekt genau einmal initialisiert wird.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
// singletonCallOnce.cpp #include <chrono> #include <iostream> #include <future> #include <mutex> #include <thread> constexpr auto tenMill= 10000000; class MySingleton{ public: static MySingleton& getInstance(){ std::call_once(initInstanceFlag, &MySingleton::initSingleton); // volatile int dummy{}; return *instance; } private: MySingleton()= default; ~MySingleton()= default; MySingleton(const MySingleton&)= delete; MySingleton& operator=(const MySingleton&)= delete; static MySingleton* instance; static std::once_flag initInstanceFlag; static void initSingleton(){ instance= new MySingleton; } }; MySingleton* MySingleton::instance= nullptr; std::once_flag MySingleton::initInstanceFlag; std::chrono::duration<double> getTime(){ auto begin= std::chrono::system_clock::now(); for ( size_t i= 0; i <= tenMill; ++i){ MySingleton::getInstance(); } return std::chrono::system_clock::now() - begin; }; int main(){ auto fut1= std::async(std::launch::async,getTime); auto fut2= std::async(std::launch::async,getTime); auto fut3= std::async(std::launch::async,getTime); auto fut4= std::async(std::launch::async,getTime); auto total= fut1.get() + fut2.get() + fut3.get() + fut4.get(); std::cout << total.count() << std::endl; } |
Zum Abschluss die Ausgabe des Programms.
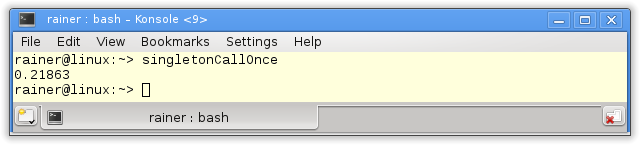
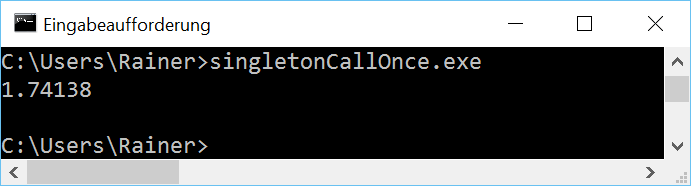
Ohne Optimierung

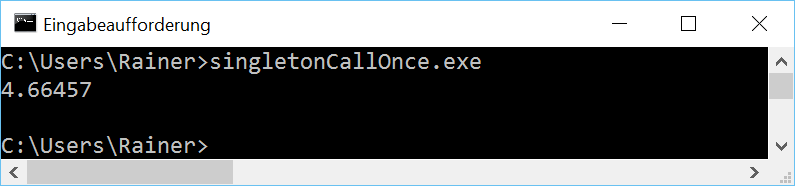
Maximale Optimierung
Die naheliegende Option ist es, den Zugriff auf das Singleton Objekt mit einem Lock zu schützen.
Lock
Der in ein Lock verpackte Mutex stellt sicher, dass die Initialisierung des Singleton Objekts threadsicher ist.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
// singletonLock.cpp #include <chrono> #include <iostream> #include <future> #include <mutex> constexpr auto tenMill= 10000000; std::mutex myMutex; class MySingleton{ public: static MySingleton& getInstance(){ std::lock_guard<std::mutex> myLock(myMutex); if ( !instance ){ instance= new MySingleton(); } // volatile int dummy{}; return *instance; } private: MySingleton()= default; ~MySingleton()= default; MySingleton(const MySingleton&)= delete; MySingleton& operator=(const MySingleton&)= delete; static MySingleton* instance; }; MySingleton* MySingleton::instance= nullptr; std::chrono::duration<double> getTime(){ auto begin= std::chrono::system_clock::now(); for ( size_t i= 0; i <= tenMill; ++i){ MySingleton::getInstance(); } return std::chrono::system_clock::now() - begin; }; int main(){ auto fut1= std::async(std::launch::async,getTime); auto fut2= std::async(std::launch::async,getTime); auto fut3= std::async(std::launch::async,getTime); auto fut4= std::async(std::launch::async,getTime); auto total= fut1.get() + fut2.get() + fut3.get() + fut4.get(); std::cout << total.count() << std::endl; } |
Wie schlägt sich die klassische threadsichere Implementierung des Singleton Patterns?
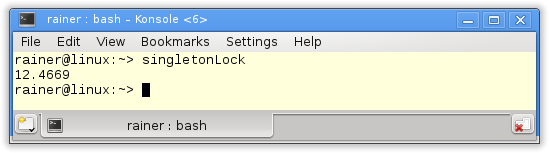
Ohne Optimierung


Maximale Optimierung
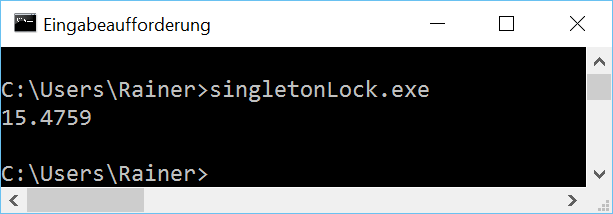
Mit atomaren Variablen solltes es deutlich schneller werden.
Atomare Operationen
Mit atomaren Variablen und deren Operationen ist die threadsichere Initialisierung des Singleton Objektes deutlich anspruchsvoller. Jetzt gelten explizit die Regeln des C++-Speichermodells. Meine Implentierungen basieren auf dem Double-Checked Locking Pattern.
Sequenzielle Konsistenz
Der Verweis auf das Singleton Objekte ist nun ein atomare Variable. Da ich die das C++-Speichermodell nicht explizit spezifiziert habe, gilt der Default: Sequenzielle Konsistenz.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
// singletonAcquireRelease.cpp #include <atomic> #include <iostream> #include <future> #include <mutex> #include <thread> constexpr auto tenMill= 10000000; class MySingleton{ public: static MySingleton* getInstance(){ MySingleton* sin= instance.load(); if ( !sin ){ std::lock_guard<std::mutex> myLock(myMutex); sin= instance.load(); if( !sin ){ sin= new MySingleton(); instance.store(sin); } } // volatile int dummy{}; return sin; } private: MySingleton()= default; ~MySingleton()= default; MySingleton(const MySingleton&)= delete; MySingleton& operator=(const MySingleton&)= delete; static std::atomic<MySingleton*> instance; static std::mutex myMutex; }; std::atomic<MySingleton*> MySingleton::instance; std::mutex MySingleton::myMutex; std::chrono::duration<double> getTime(){ auto begin= std::chrono::system_clock::now(); for ( size_t i= 0; i <= tenMill; ++i){ MySingleton::getInstance(); } return std::chrono::system_clock::now() - begin; }; int main(){ auto fut1= std::async(std::launch::async,getTime); auto fut2= std::async(std::launch::async,getTime); auto fut3= std::async(std::launch::async,getTime); auto fut4= std::async(std::launch::async,getTime); auto total= fut1.get() + fut2.get() + fut3.get() + fut4.get(); std::cout << total.count() << std::endl; } |
Nun bin ich gespannt.
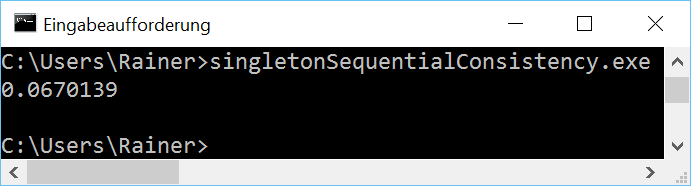
Ohne Optimierung
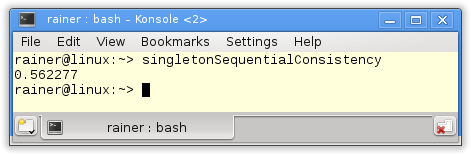
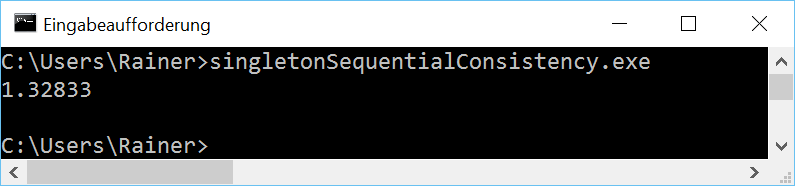
Maximale Optimierung
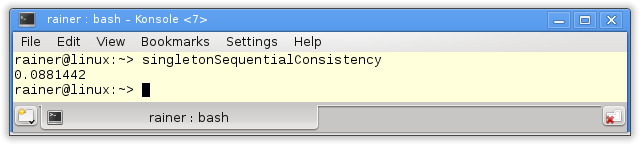
Eine weitere Optimierungsmöglichkeit für atomare Operationen will ich noch anwenden.
Acquire-Release Semantik
Das Lesen auf dem Singleton Objekt (Zeile 14) ist eine acquire-Operation, das Schreiben auf dem Singleton-Objekt ist eine release-Operation (Zeile 20). Da beide Operationen auf der gleichen atomaren Variablen vollzogen werden, ist in diesem Fall die strenge Sequenzielle Konsistenz nicht notwendig. Der C++-Standard sichert zu, dass eine acquire-Operation mit einer davor ausgeführen release-Operation synchronisiert, wenn sie auf der gleichen atomaren Variablen ausgeführt werden. Diese Bedingung gilt in unserem konkreten Fall. Daher lockere ich die Bedingungen an das C++-Speichermodell in Zeile 14 und 20 und verwende die Acquire-Release Semantik.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
// singletonAcquireRelease.cpp #include <atomic> #include <iostream> #include <future> #include <mutex> #include <thread> constexpr auto tenMill= 10000000; class MySingleton{ public: static MySingleton* getInstance(){ MySingleton* sin= instance.load(std::memory_order_acquire); if ( !sin ){ std::lock_guard<std::mutex> myLock(myMutex); sin= instance.load(std::memory_order_relaxed); if( !sin ){ sin= new MySingleton(); instance.store(sin,std::memory_order_release); } } // volatile int dummy{}; return sin; } private: MySingleton()= default; ~MySingleton()= default; MySingleton(const MySingleton&)= delete; MySingleton& operator=(const MySingleton&)= delete; static std::atomic<MySingleton*> instance; static std::mutex myMutex; }; std::atomic<MySingleton*> MySingleton::instance; std::mutex MySingleton::myMutex; std::chrono::duration<double> getTime(){ auto begin= std::chrono::system_clock::now(); for ( size_t i= 0; i <= tenMill; ++i){ MySingleton::getInstance(); } return std::chrono::system_clock::now() - begin; }; int main(){ auto fut1= std::async(std::launch::async,getTime); auto fut2= std::async(std::launch::async,getTime); auto fut3= std::async(std::launch::async,getTime); auto fut4= std::async(std::launch::async,getTime); auto total= fut1.get() + fut2.get() + fut3.get() + fut4.get(); std::cout << total.count() << std::endl; } |
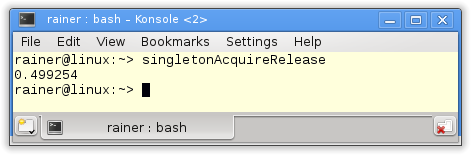
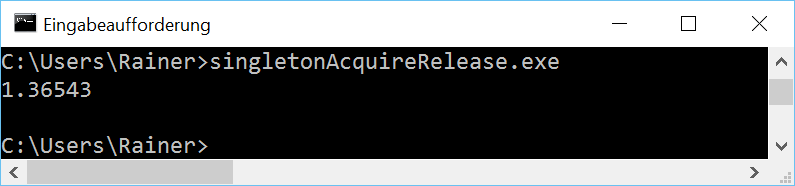
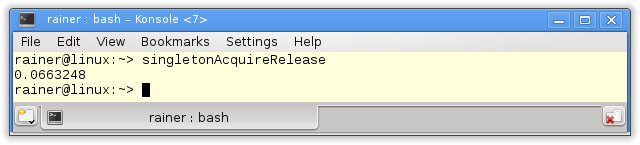
Die Acquire-Release Semantik besitzt eine ähnliche Performanz wie die Sequenzielle Konsistenz. Das verwundert mich nicht, denn auf x86-Architekturen sind beide Speichermodelle sehr ähnlich. Auf einer ARMv7- oder PowerPC-Architektur sind die Unterschiede deutlich drastischer. Die Details dazu gibt es auf Jeff Preshings Blog Preshing on Programming.
Ohne Optimierung
Maximale Optimierung

Habe ich eine wichtige Variante der threadsicheren Initialisierung eines Singleton Objektes vergessen? Wenn ja, schicke mir deine threadsichere Singleton Implementierung zu und ich werde sie in die Aufstellung aufnehmen.
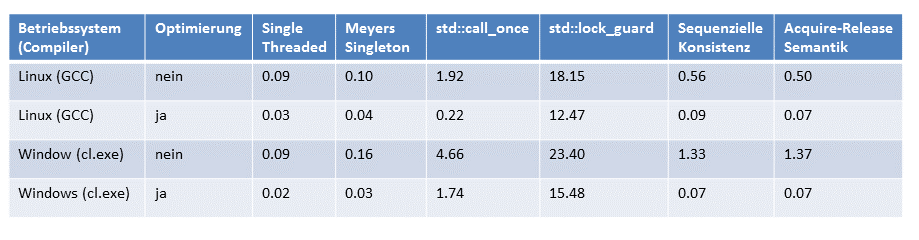
Alle Zahlen im Überblick
Da ich alle Programme nur einmalig ausgeführt habe und die ausführbaren Dateien für Windows auf vier Kerne optimiert habe, obwohl ich nur zwei besitze, will ich die Zahlen nicht überbewerten. Sie geben aber ein deutliches Zeichen. Das Meyers Singleton ist sehr einfach zu verstehen und besitzt die beste Performanz. Insbesondere die auf Locks basierende Version ist deutlich langsamer. Diese Aussagen gelten unabhängig davon, ob ich die Programme mit dem GCC- oder dem cl.exe-Compiler übersetzt habe.
Schön zeigen die vielen Zahlen aber auch, das sich das Optimieren lohnt. Diese Aussage gilt nur mit leichter Einschränkung für die Lock Implementierung des Singleton Patterns, das intern std::lock_guard verwendet.
Wie geht's weiter?
Nachdem ich doch mit dem Artikel zu Singletons sehr stark polarisiert haben, will auf meine Meinung zum Singleton im nächsten Artikel deutlich eingehen. Mal schauen, in welche Richtung sich die Diskussion noch weiter bewegt.
 Go to Leanpub/cpplibrary "What every professional C++ programmer should know about the C++ standard library". Hole dir dein E-Book. Unterstütze meinen Blog.
Go to Leanpub/cpplibrary "What every professional C++ programmer should know about the C++ standard library". Hole dir dein E-Book. Unterstütze meinen Blog.






Weiterlesen...