In C++11 wurde die Initialisierung von Variablen vereinheitlicht. In jedem Kontext ist die {}-Initialisierung anwendbar. Daher wird auch gerne von der vereinheitlichten Initialisierung mit {} gesprochen.
Überall anwendbar
Der Einfachheit halber werde ich von vereinheitlichten Initialisierung mit {} im Rest des Artikels einfach von der {}-Initialisierung sprechen. Bevor ich aber auf zwei wichtigsten Implikationen der {}-Initialisierung in sicherheitskritischer Software eingehe, will ich ein paar besondere Anwendungsfälle vorstellen. Diese sind erst mit C++11 möglich.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
#include <map> #include <vector> #include <string> // Initialization of a C-Array as attribute of a class class Array{ public: Array(): myData{1,2,3,4,5}{} private: int myData[5]; }; class MyClass{ public: int x; double y; }; class MyClass2{ public: MyClass2(int fir, double sec):x{fir},y{sec} {}; private: int x; double y; }; int main(){ // Direct Initialization of a standard container int intArray[]= {1,2,3,4,5}; std::vector<int> intArray1{1,2,3,4,5}; std::map<std::string,int> myMap{{"Scott",1976}, {"Dijkstra",1972}}; // Initialization of a const heap array const float* pData= new const float[3]{1.1,2.2,3.3}; Array arr; // Defaut Initialization of a arbitrary object int i{}; // i becomes 0 std::string s{}; // s becomes "" std::vector<float> v{}; // v becomes an empty vector double d{}; // d becomes 0.0 // Initializations of an arbitrary object using public attributes MyClass myClass{2011,3.14}; MyClass myClass1= {2011,3.14}; // Initializations of an arbitrary object using the constructor MyClass2 myClass2{2011,3.14}; MyClass2 myClass3= {2011,3.14}; } |
Alles der Reihe nach. Die direkte Initialisierung des C-Arrays, des std::vector und der std::map geht in den Zeilen 30 - 32 sehr einfach von der Hand. Beim std::map sind die inneren {}-Paare die Schlüsse und Wert Paare. Mit der direkten Initialisierung eines konstanten C-Array auf dem Heap geht es in Zeile 35 weiter. Das besondere des Array arr in Zeile 37 ist es, das sein C-Array direkt in der Konstruktor-Initialisierungsliste in Zeile 8 initialisiert wird. Die Default-Initialisierung in Zeile 40 - 43 hat es in sich. Werden hier statt den geschweiften Klammern runde Klammern verwendet, kommt es zu dem berühmt berüchtigten most vexing parse. Das klingt nicht gut. Dazu gleich mehr. In den Zeilen 46 und 47 werden die öffentlichen Attribute des Objekts direkt initialisiert. Auch der Konstruktor kann in den Zeilen 50 und 51 direkt aufgerufen werden.
auto
Immer anwendbar? Ja, aber du musst eine spezielle Regel im Kopf behalten. Wenn du automatische Typableitung mit auto in Kombination mit einer {}-Initialisierung verwendest, erhält du eine std::initializer_list.
auto initA{1}; // std::initializer_list<int> auto initB= {2}; // std::initializer_list<int> auto initC{1, 2}; // std::initializer_list<int> auto initD= {1, 2}; // std::initializer_list<int>
Dies Verhalten wird sich in C++17 mit großer Wahrscheinlichkeit ändern.
auto initA{1}; // int auto initB= {2}; // std::initializer_list<int> auto initC{1, 2}; // error, no single element auto initD= {1, 2}; // std::initializer_list<int>
Um ehrlich zu sein, ich mag das neue Verhalten nicht. Die C++11 Semantik ist für mich relativ klar. Wenn ich {}-Initialisierung mit auto verwende, bekomme ich eine std::initializer_list. Mit C++17 muss ich aber zwei Regeln im meinem Kopf behalten.
- Es macht einen Unterschied, ob ich Direkt- oder Copy-Initialisierung verwende.
- Es macht einen Unterschied, ob ich ein oder mehrere Elemente in meiner {}-Initialiserung verwende.
Most vexing parse
Was heißt das überhaupt? Das ärgerlichste Parse-Problem. Zu mindestens wurde der Ausdruck in Wikipedia aufgenommen: https://en.wikipedia.org/wiki/Most_vexing_parse. Die Geschichte ist schnell erzählt. Fast jeder C++-Entwickler ist wohl schon in die Falle gefallen. Die meisten haben es aber mittlerweile verdrängt.
Zuerst ein kleines Programm, das das Problem auf den Punkt bringt.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#include <iostream> struct MyInt{ MyInt(int i):i(i){} MyInt():i(0){} int i; }; int main(){ MyInt myInt(2011); MyInt myInt2(); std::cout << myInt.i << std::endl; std::cout << myInt2.i << std::endl; } |
MyInt in Zeile 3 - 7 ist ein einfacher Wrapper um die natürliche Zahl i. Diese Zahl kann mit dem Konstruktor in Zeile 4 auf einen expliziten Wert initialisiert werden. Im Gegensatz dazu initialisiert der Default-Konstruktor in Zeile 5 i auf 0. So weit, so gut. In den Zeilen 12 und 13 wende ich die beiden Konstruktoren an und gebe in den anschließenden Zeilen die Werte der Variablen i aus. Schnell das Programm übersetzt und ausgeführt.
Das Übersetzen des Programms schlägt aber fehl.
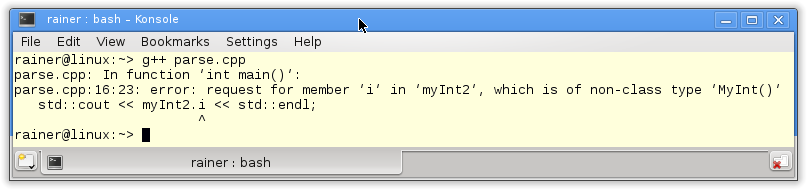
Die Fehlermeldung ist auch nicht besonders aussagekräftig. Der Compiler kann den Ausdruck in Zeile 13 sowohl als Aufruf des Default-Konstruktors als auch als Deklaration einer Funktion interpretieren. Im Zweifelsfall muss er sich aber für letzteres entscheiden. Das zeigt das leicht modifizierte Programm.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
#include <iostream> #include <typeinfo> struct MyInt{ MyInt(int i):i(i){} MyInt():i(0){} int i; }; MyInt myFunction(); int main(){ MyInt myInt(2011); MyInt myInt2(); std::cout << typeid(myInt2).name() << std::endl; std::cout << typeid(myFunction).name() << std::endl; } |
In Zeile 10 deklariere ich eine Funktion myFunction, die kein Argument erwartet und ein Typ MyInt zurück gibt. Genau die gleiche Signatur hat die Funktionsdeklaration in Zeile 15. Das zeigt schön die Ausgabe der Typinformation mit dem typeid-Operator.

Die Lösung des Problems ist recht einfach. Werden anstelle der runden Klammern in den Zeilen 10 und 15 geschweifte Klammern verwendet, kann der Compiler den Ausdruck nicht als Funktionsdeklaration interpretieren. Genau diese Eigenschaft der {}-Initialisierung habe ich bereits im ersten Beispiel dieses Artikels in den Zeilen 40 - 43 angewandt.
Nun aber zu der Eigenschaft der {}-Initialisierung, das sie so wertvoll für die sicherheitskritische Programmierung macht. Sie verhindert Verengung (narrowing).
Verengung verhindern
Verengung oder genau gesagt verengende Konvertierung (narrowing conversion) bezeichnet eine implizite Konvertierung arithmetischer Typen unter Verlust der Datengenauigkeit. Das hört sich nicht gut an.
Das kleine Beispiel stellt die Problematik mit klassischer Initialisierung für built-in Datentypen vor. Dabei ist es unerheblich, ob die Variable direkt oder durch Zuweisung initialisiert wird.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#include <iostream> int main(){ char c1(999); char c2= 999; std::cout << "c1: " << c1 << std::endl; std::cout << "c2: " << c2 << std::endl; int i1(3.14); int i2= 3.14; std::cout << "i1: " << i1 << std::endl; std::cout << "i2: " << i2 << std::endl; } |
Die Ausgabe des Programms zeigt zwei Dinge. Zum einen passt das Literal 999 nicht in den Datentyp char, zum andern wird das Literal 3.14 abgeschnitten.
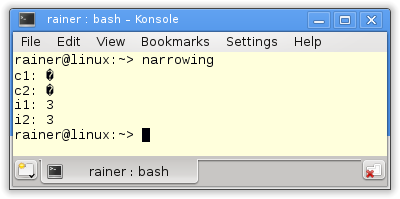
Das ändert sich mit der {}-Initialisierung.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#include <iostream> int main(){ char c1{999}; char c2= {999}; std::cout << "c1: " << c1 << std::endl; std::cout << "c2: " << c2 << std::endl; int i1{3.14}; int i2= {3.14}; std::cout << "i1: " << i1 << std::endl; std::cout << "i2: " << i2 << std::endl; } |
Das Programm ist ill-formed und ist damit syntaktisch falsch. Der Compiler muss bei der Verengung mit {}-Initialisierung zu mindestens eine Warnung ausgeben. Auch wenn das Programm ill-formed ist, muss es der Compiler aber nicht ablehnen.
Und nun beginnt die maximale Verwirrung mit dem GCC. Hier unterscheidet sich das Verhalten der ältere GCC 4.7 von meinem aktuellen GCC 4.8 Compiler. Was für den GCC 4.7 eine Fehlermeldung war, ist dem GCC 4.8 nur noch eine Warnung wert. Mit dem GCC 5.1 ist es wieder ein Fehler. Schön lässt sich die Verwirrung auf dem interaktiven Online-Compiler https://gcc.godbolt.org/ nachvollziehen. Hier ist der clang++ deutlich berechenbarer. Daher mein Tipp. Übersetze dein Programm immer so, dass Verengungen als Fehler interpretiert werden. Genau davon habe ich meinen GCC 4.8 überzeugt, indem ich das Flag -Werror=narrowing gesetzt habe.

Eine kleine Anmerkung noch zum Schluss. Ein Ausdruck char c3{8} ist keine Verengung, da die Zahl 8 in den Datentyp char passt. Das gleiche gilt natürlich auch für char c3= {8}.
Wie geht's weiter?
Mit static_assert und der Type-Traits Bibliothek erhielt C++11 zwei mächtige Feature, die es erlauben, den Code zu Compilezeit syntaktisch zu prüfen. Im nächsten Artikel werde ich den neuen Operator static_assert und sein Zusammenspiel mit der Type-Traits Bibliothek genauer vorstellen.
 Go to Leanpub/cpplibrary "What every professional C++ programmer should know about the C++ standard library". Hole dir dein E-Book. Unterstütze meinen Blog.
Go to Leanpub/cpplibrary "What every professional C++ programmer should know about the C++ standard library". Hole dir dein E-Book. Unterstütze meinen Blog.






Weiterlesen...