Acquire und release Speicherbarrieren (fences) garantieren ähnliche Synchronisations- und Ordnungsbedingungen wie atomare Operationen mit Acquire-Release-Semantik. Ähnliche, denn die Unterschiede stecken im Detail.
Der offensichtlichste Unterschied zwischen acquire- und release-Speicherbarrieren und atomaren Operationen mit Acquire-Release-Semantik ist es, dass Speicherbarrieren ohne atomare Operationen auskommen. Es gibt aber einen viel feineren Unterschied. Die acquire- und release-Speicherbarrieren sind schwergewichtiger.
Atomare Operationen versus Speicherbarrieren
Der Einfachheit halber spreche ich nun nur noch von acquire-Operationen, wenn ich eine Speicherbarriere oder eine atomare Operation mit acquire-Semantik betrachte. Im gleichen Sinne spreche ich von release-Operartionen.
Die zentrale Idee einer acquire- und einer release-Operation ist es, dass sie eine Synchronisations- und Ordnungsbedingung zwischen Threads etablieren, die auch für atomare Operationen mit Relaxed-Semantik und nichtatomare Operationen gilt. Daher treten die acquire- und release-Operationen im Paar auf. Für die atomaren Operationen mit Acquire-Release-Semantik gilt darüber hinaus, dass sie auf der gleichen atomaren Variable stattfinden müssen. Trotzdem werde ich in erster Annäherung beide Operationen isoliert betrachten.
Anfangen werde ich mit der acquire-Operation.
Acquire-Operation
Ein Lese-Operation auf einer atomaren Variable mit dem std::memory_order_acquire versehen, ergibt eine acquire-Operation.

Dem gegenüber steht der std::atomic_thread_fence mit acquire-Semantik.

Die Gegenüberstellung zeigt schön zwei Punkte:
- Ein Speicherbarriere mit acquire-Semantik stellt strengere Ordnungsbedingungen auf. Zwar fordert sowohl die acquire-Operation auf der atomaren Variable als auch die acquire-Speicherbarriere, dass keine Lese- und Schreibe-Operationen vor die acquire-Operation verschoben werden können. Darüber hinaus garantiert die acquire-Speicherbarriere zusätzlich, dass keine Lese-Operationen hinter sie verschoben werden kann.
- Für das Lesen der atomaren Variable var ist die Relaxed-Semantik ausreichend. Der std::atomic_thread_fence(std::memory_order_acquire) verhindert, dass diese Operation hinter diesen umsortiert werden kann.
Ähnlich Aussagen gelten für die release-Speicherbarriere
Release-Operation
Ein Schreibe-Operation auf einer atomaren Variable mit dem std::memory_order_release versehen, ergibt eine release-Operation.

Weiter geht es mit der release-Speicherbarriere.

Zusätzlich zur release-Operation auf der atomaren Variable var sichert die release-Speicherbarriere zwei Eigenschaften zu:
- Schreibe-Operationen können nicht vor die Speicherbarriere verschoben werden.
- Für die Variable var ist es ausreichend, dass sie der Relaxed-Semantik genügt.
Wer den einfachen Überblick zu den Speicherbarrieren sucht, den verweise ich gerne auf den letzten Artikel dieses Blogs. Nun will ich einen Schritt weiter gehen und aus den Bausteinen ein Programm zusammenstellen.
Synchronisation mit atomaren Operationen versus Speicherbarrieren
Als Ausgangspunkt für meinen Vergleich implementiere ich einen typischen Consumer-Producer Arbeitsablauf mit Acquire-Release-Semantik. Diesen Ablauf werde ich mit atomaren Variablen und Speicherbarrieren umsetzen.
Los geht's mit atomaren Variablen, da viele Entwickler mit diesen bereits vertraut sind. Dies gilt aber nicht für Speicherbarrieren. Sie werden fast vollständig in der Literatur zum C++-Speichermodell ignoriert.
Atomare Operationen
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
// acquireRelease.cpp #include <atomic> #include <thread> #include <iostream> #include <string> std::atomic<std::string*> ptr; int data; std::atomic<int> atoData; void producer(){ std::string* p = new std::string("C++11"); data = 2011; atoData.store(2014,std::memory_order_relaxed); ptr.store(p, std::memory_order_release); } void consumer(){ std::string* p2; while (!(p2 = ptr.load(std::memory_order_acquire))); std::cout << "*p2: " << *p2 << std::endl; std::cout << "data: " << data << std::endl; std::cout << "atoData: " << atoData.load(std::memory_order_relaxed) << std::endl; } int main(){ std::cout << std::endl; std::thread t1(producer); std::thread t2(consumer); t1.join(); t2.join(); delete ptr; std::cout << std::endl; } |
Wem das Programm bekannt vorkommt, darf sich nicht wundern. Dies ist ein Klassiker, den ich bereits in dem Artikel zum memory_order_consume verwendet habe. Die Graphik bringt direkt auf den Punkt, warum der Consumer-Thread t2 alle Werte des Producer-Thread t1 sieht.
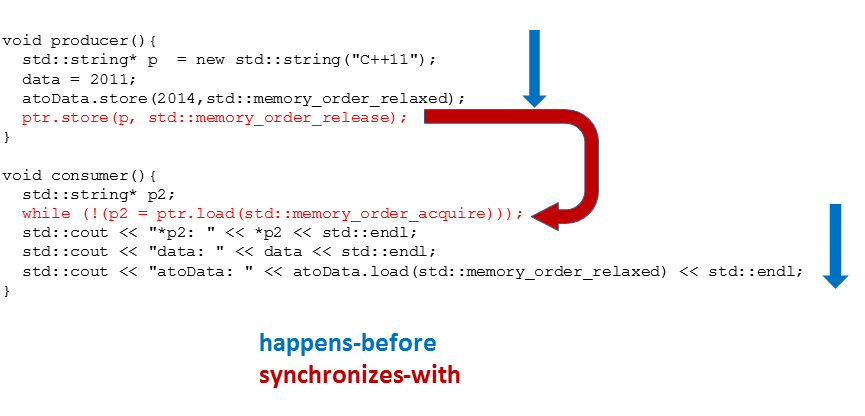
Die Wohldefiniertheit des Programms ist gewährleistet, da die happens-before Beziehung transitiv ist. Dazu müssen die drei happens-before Beziehungen verknüpft werden:
- Die Zeile 13 - 15 happens-before Zeile 16 (ptr.store(p,std::memory_order_release).
- Die Zeile 21 while(!(p2= ptrl.load(std::memory_order_acquire))) happens-before den Zeilen 22 - 24.
- Die Zeile 16 synchronizes-with Zeile 21. => Die Zeile 16 happens-before Zeile 21.
Jetzt wird es spannend. Wie lässt sich der Ablauf auf Speicherbarrieren umstellen?
Speicherbarrieren
Das Programm ist schnell auf Speichbarrieren portiert.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
// acquireReleaseFences.cpp #include <atomic> #include <thread> #include <iostream> #include <string> std::atomic<std::string*> ptr; int data; std::atomic<int> atoData; void producer(){ std::string* p = new std::string("C++11"); data = 2011; atoData.store(2014,std::memory_order_relaxed); std::atomic_thread_fence(std::memory_order_release); ptr.store(p, std::memory_order_relaxed); } void consumer(){ std::string* p2; while (!(p2 = ptr.load(std::memory_order_relaxed))); std::atomic_thread_fence(std::memory_order_acquire); std::cout << "*p2: " << *p2 << std::endl; std::cout << "data: " << data << std::endl; std::cout << "atoData: " << atoData.load(std::memory_order_relaxed) << std::endl; } int main(){ std::cout << std::endl; std::thread t1(producer); std::thread t2(consumer); t1.join(); t2.join(); delete ptr; std::cout << std::endl; } |
Zum einen füge ich an Stelle der atomaren Operationen mit acquire- und release-Semantik die entsprechenden Speicherbarrieren mit acquire- und release-Semantik (Zeile 16 und 23) ein, zum anderen verwende ich für die atomaren Operationen mit acquire- und release-Semantik die Relaxed-Semantik (Zeile 17 und 22). Das ist fast schon mechanisch. Natürlich kann ich auch nur eine acquire- oder release-Operation durch eine Speicherbarriere ersetzen. Der entscheidende Punkt ist, dass die release-Operation mit der acquire-Operation eine synchronizes-with Beziehung und damit eine happens-before Beziehung etabliert.
Die ganzen Zusicherungen möchte ich noch in bekannter Manier anhand einer Graphik erläutern.

Die entscheidende Frage ist, warum die Operationen, die der acquire-Speicherbarriere folgen, die Effekte der Operationen vor der release-Speicherbarriere sehen? Da data eine nichtatomare Variable ist und die atomare Variable atoData der Relaxed-Semantik folgt, können sie per se umsortiert werden. Dies ist aber nicht möglich, da std::atomic_thread_fence(std::memory_order_release) als release-Speicherbarriere, std::atomic_thread_fence(std::memory_order_acquire) als acquire-Speicherbarriere die potentielle Umsortierung unterbindet. Die detailiierte Begründung dazu findest du in der Analyse der acquire- und release-Speicherbarrieren am Anfang dieses Artikels.
Der Übersichtlichkeit halber die ganze Argumentation kurz und knackig.
- Die acquire- und release-Speicherbarrieren verhindern das Umsortieren der atomaren und nichtatomaren Operationen über die Speicherbarrieren hinaus.
- Der Consumer-Thread t2 wartet in der Schleife while (!(p2= ptr.load(std::memory_order_relaxed))) auf das Setzen des Zeigerwertes ptr.stor(p,std::memory_order_relaxed) im Producer-Thread t1.
- Die release-Speicherbarriere synchronizes-with der acquire-Speicherbarriere.
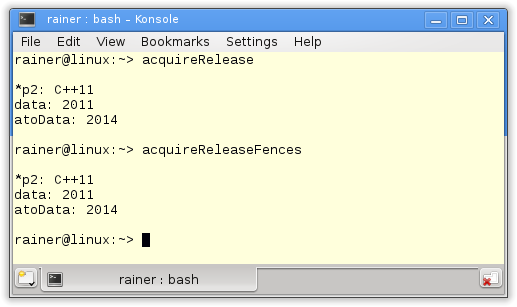
Zum Abschluss noch die Ausgabe der beiden Programme.
Wie geht's weiter?
Wenn ich eines bei meiner Beschäftigung mit dem C++-Speichermodell gelernt habe, ist es, dass ich meiner Intuition nicht trauen kann. Daher sind formale Verifizierungswerkzeuge so wertvoll. Dank dem online verfügbaren C++-Speichermodell Evaluierer CppMem ist es einfach möglich, die Wohldefiniertheit von Codeabschnitten zu verifizieren. Im nächsten Artikel werde ich CppMem genauer vorstellen.
 Go to Leanpub/cpplibrary "What every professional C++ programmer should know about the C++ standard library". Hole dir dein E-Book. Unterstütze meinen Blog.
Go to Leanpub/cpplibrary "What every professional C++ programmer should know about the C++ standard library". Hole dir dein E-Book. Unterstütze meinen Blog.






Weiterlesen...