std::memory_order_consume ist das legendärste der sechs Speichermodelle. Dieser besondere Ruf ist zwei Tatsachen geschuldet. Zum einen ist die std::memory_order_consume Ordnung sehr verständnisresistent. Zum andern hat es meines Wissens noch kein Compiler umgesetzt.
Wie kann es sein, dass ein Compiler den C++11-Standard unterstützt, wenn er den Speichermodell-Bezeichner std::memory_order_consume noch nicht umgesetzt hat? Die Antwort ist, dass std::memory_order_consume von den Compilern auf std::memory_order_acquire abgebildet wird. Das ist zulässig, denn beide sind load oder auch aquire-Operationen. std::memory_order_consume stellt nur schwächere Synchronisations- und Ordnungsbedingungen. Damit ist eine Release-Acquire-Ordnung potentiell langsamer als eine Release-Consume-Ordnung aber, und das ist der entscheidende Punkt, wohldefiniert.
Um die Release-Consume-Ordnung zu verstehen, bietet es sich natürlich an, diese in Kontrast zu der Release-Acquire-Ordnung zu stellen. Ich spreche in diesem Artikel bewusst von Release-Acquire-Ordnung und nicht von Acquire-Release-Semantik, um die enge Verwandtschaft von std::memory_order_acquire und std::memory_order_consume deutlich auf den Punkt zu bringen.
Release-Acquire-Ordnung
Als Ausgangsprogramm dienen mir die zwei Threads t1 und t2, in der t1 die Rolle des Produzenten, in der t2 die Rolle des Konsumenten einnimmt. Die atomare Variable ptr dient dazu, Produzent und Konsument zu synchronisieren.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
// acquireRelease.cpp #include <atomic> #include <thread> #include <iostream> #include <string> std::atomic<std::string*> ptr; int data; std::atomic<int> atoData; void producer(){ std::string* p = new std::string("C++11"); data = 2011; atoData.store(2014,std::memory_order_relaxed); ptr.store(p, std::memory_order_release); } void consumer(){ std::string* p2; while (!(p2 = ptr.load(std::memory_order_acquire))); std::cout << "*p2: " << *p2 << std::endl; std::cout << "data: " << data << std::endl; std::cout << "atoData: " << atoData.load(std::memory_order_relaxed) << std::endl; } int main(){ std::cout << std::endl; std::thread t1(producer); std::thread t2(consumer); t1.join(); t2.join(); std::cout << std::endl; } |
Bevor ich zur genaueren Analyse des Programms komme, will ich erst eine kleine Variation einführen. In dieser ersetze ich in der Zeile 21 die Speicherordnung std::memory_order_acquire durch std::memory_order_consume.
Release-Consume-Ordnung
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
// acquireConsume.cpp #include <atomic> #include <thread> #include <iostream> #include <string> std::atomic<std::string*> ptr; int data; std::atomic<int> atoData; void producer(){ std::string* p = new std::string("C++11"); data = 2011; atoData.store(2014,std::memory_order_relaxed); ptr.store(p, std::memory_order_release); } void consumer(){ std::string* p2; while (!(p2 = ptr.load(std::memory_order_consume))); std::cout << "*p2: " << *p2 << std::endl; std::cout << "data: " << data << std::endl; std::cout << "atoData: " << atoData.load(std::memory_order_relaxed) << std::endl; } int main(){ std::cout << std::endl; std::thread t1(producer); std::thread t2(consumer); t1.join(); t2.join(); std::cout << std::endl; } |
Das war einfach. Leider besitzt das Programm undefiniertes Verhalten. Diese Aussage ist natürlich sehr hypothetisch, da mein Compiler std::memory_order_consume durch std::memory_order_acquire umsetzt.
Release-Acquire- versus Release-Consume-Ordnung
Die Ausgabe der beiden Programme ist identisch.
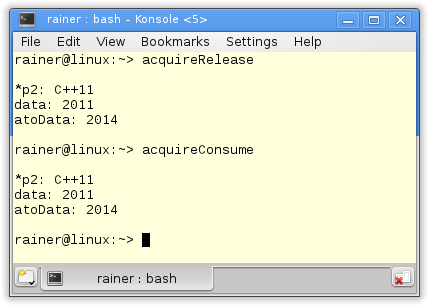
Auch wenn es mich natürlich wiederhole, will ich kurz skizzieren, warum das erste Programm acquireRelease.cpp wohldefiniert ist.
Die store-Operation in Zeile 16 synchronizes-with der load-Operation in 21. Das ist dadurch begründet, dass die store-Operation mit std::memory_order_release, dass die load-Operation mit std::memory_order_acquire versehen ist.Weiter gilt, das durch diese Release-Acquire-Ordnung alle Operation, die vor der store-Operation in Zeile 16 im Sourcecode stehen, nach der load-Operation in der Zeile 21 zur Verfügung stehen. Damit synchronisiert die Release-Acquire-Ordnung auch den Zugriff auf die nicht atomare Variable data in Zeile 14 und die atomare Variable atoData in Zeile 15, obwohl diese mit dem Bezeichner std::memory_order_relaxed annotiert ist.
Was ändert sich nun, wenn ich in dem Programm std::memory_order_acquire durch std::memory_order_consume ersetze?
Datenabhängigkeiten mit std::memory_order_consume
In der std::memory_order_consume geht es um Datenabhängigkeiten auf atomaren Datentypen. Diese gibt es in zwei Formen. Zum einen carries-a-dependency-to in einem Thread und dependency-ordered-before zwischen zwei Threads. Beide Abhängigkeiten implizieren eine happens-before Ordnung. Das ist genau die Beziehung, die ein wohldefiniertes Programm benötigt. Doch was heißt carries-a-dependency-to und dependency-ordered-before?
- carries-a-dependency-to: Wenn das Ergebnis einer Operation A als Operand einer Operation B verwendet wird, dann gilt. A carries-a-dependency-to B.
- dependecy-ordered-before: Eine store-Operation A (mit std::memory_order_release, std::memory_order_acq_rel oder std::memory_order_seq_cst versehen), ist dependency_ordered_before einer load-Operation B (mit std::memory_order_consume versehen), wenn das Ergebnis der load-Operation B in einer weiteren Operation C im selben Thread wie die Operation B verwendet wird.
Mir ist natürlich klar, dass diese zwei Definitionen sehr schwer verdaulich sind. Daher will ich die Datenabhängigkeiten an der Graphik verdeutlichen.

Der Ausdruck ptr.store(p, std::memory_order_release) ist dependency-ordered-before while (!(p2 = ptr.load(std::memory_order_consume))), da in der anschließenden Zeile std::cout << "*p2: " << *p2 << std::endl das Ergebnis der load-Operation gelesen wird. Dabei gilt: while (!(p2 = ptr.load(std::memory_order_consume)) carries-a-dependency-to std::cout << "*p2: " << *p2 << std::endl, da die Ausgabe von *p2 das Ergebnis der ptr.load-Operation verwendet.
Für die anschließenden Ausgaben von data und atoData sind die Werte nicht zugesichert. Dies gilt, da ihre Werte keine carries-a-dependency Beziehung zu ptr.load-Operation besitzen. Es wird noch schlimmer. Da data keine atomare Variable ist, besteht ein kritischer Wettlauf um data. Der Grund für den kritischen Wettlauf ist es, da beide Threads auf data gleichzeitig zugreifen können und Thread t1 data in der Funktion producer dabei modifiziert. Damit ist das Programmverhalten undefiniert.
Wie geht's weiter?
Zugegeben, das war ein anspruchsvoller Artikel. Im nächsten Artikel gehe ich tiefer auf den typischen Fehler der Acquire-Rlease-Semantik ein. Dieser tritt ein, wenn die acquire-Operation vor der release-Operation stattfindet.
 Go to Leanpub/cpplibrary "What every professional C++ programmer should know about the C++ standard library". Hole dir dein E-Book. Unterstütze meinen Blog.
Go to Leanpub/cpplibrary "What every professional C++ programmer should know about the C++ standard library". Hole dir dein E-Book. Unterstütze meinen Blog.






Weiterlesen...