Im Gegensatz zum dem std::atomic_flag sind alle weiteren atomaren Datentypen partielle oder vollständige Spezialisierungen des Klassen-Templates std::atomic. Den Anfang macht std::atomic<bool>.
std::atomic<bool>
Der atomare boolesche Wahrheitswert std::atomic<bool> ist deutlich mächtiger als das atomare Flag std::atomic_flag. Er kann explizit auf true oder false gesetzt werden. Diese Operationen sind ausreichend, um zwei Threads zu synchronisieren. Damit lassen sich Bedingungsvariablen mit atomaren Variablen implementieren.
Zuerst die klassische Bedingungsvariable.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
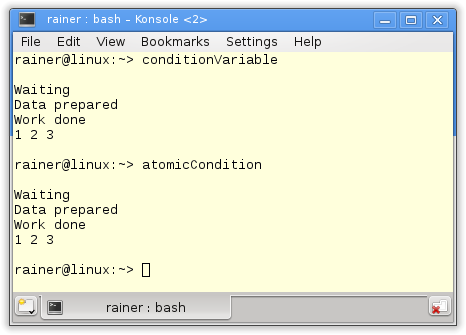
// conditionVariable.cpp #include <condition_variable> #include <iostream> #include <thread> #include <vector> std::vector<int> mySharedWork; std::mutex mutex_; std::condition_variable condVar; bool dataReady; void waitingForWork(){ std::cout << "Waiting " << std::endl; std::unique_lock<std::mutex> lck(mutex_); condVar.wait(lck,[]{return dataReady;}); mySharedWork[1]= 2; std::cout << "Work done " << std::endl; } void setDataReady(){ mySharedWork={1,0,3}; { std::lock_guard<std::mutex> lck(mutex_); dataReady=true; } std::cout << "Data prepared" << std::endl; condVar.notify_one(); } int main(){ std::cout << std::endl; std::thread t1(waitingForWork); std::thread t2(setDataReady); t1.join(); t2.join(); for (auto v: mySharedWork){ std::cout << v << " "; } std::cout << "\n\n"; } |
Und nun die atomare Variante.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
// atomicCondition.cpp #include <atomic> #include <chrono> #include <iostream> #include <thread> #include <vector> std::vector<int> mySharedWork; std::atomic<bool> dataReady(false); void waitingForWork(){ std::cout << "Waiting " << std::endl; while ( !dataReady.load() ){ // (3) std::this_thread::sleep_for(std::chrono::milliseconds(5)); } mySharedWork[1]= 2; // (4) std::cout << "Work done " << std::endl; } void setDataReady(){ mySharedWork={1,0,3}; // (1) dataReady= true; // (2) std::cout << "Data prepared" << std::endl; } int main(){ std::cout << std::endl; std::thread t1(waitingForWork); std::thread t2(setDataReady); t1.join(); t2.join(); for (auto v: mySharedWork){ std::cout << v << " "; } std::cout << "\n\n"; } |
Wieso ist zugesichert, dass die Zeile 17 nach der Zeile 14 ausgeführt wird? Oder noch allgemeiner ausgedrückt, dass der Thread t1 erst dann mySharedWork[1]= 2 in Zeile 17 ausführt, nachdem Thread t2 in Zeile 22 mySharedWork={1,0,3} gesetzt hat. Jetzt wird es mathematisch. Um keine weitere Verwirrung zu stiften, verwende ich die englische Begrifflichkeit.
- Zeile 22 (1) happens-before Zeile 23 (2)
- Zeile 14 (3) happens-before Zeile 17 (4)
- Zeile 23 (2) synchronizes-with Zeile 14 (3)
- Da happens-before transitiv ist, gilt: mySharedWork={1,0,3} (1) happens-before mySharedWork[1]= 2 (4)
Auf eine Besonderheit des beiden Programme will ich gerne noch explizit hinweisen. Dank der Bedingungsvariable condVar bzw. der atomaren Variable dataReady wird der Zugriff auf die gemeinsame Variable mySharedWork synchronisiert, obwohl diese weder durch einen Lock geschützt ist oder selbst eine atomare Variable ist.
Beide Programme geben die gleichen Ergebnisse für mySharedWork.
Push- versus Pull-Prinzip
Natürliich habe ich ein wenig geschummelt. Ein Unterschied besteht zwischen der Bedingungsvariable und dem atomaren Wahrheitswert zur Synchronisation von Threads besteht. Während die Bedingungsvariable dem wartenden Thread signalisiert (condVar.notify()), dass er mit seiner Arbeit fortsetzen kann, schläft der wartende Thread mit seiner atomaren Variable und prüft, ob der sendende Thread mit seiner Arbeit fertig ist (dataRead= true).
Die Bedingungsvariable benachrichtigt den wartenden Thread (Push-Prinzip). Die atomare Variable frägt permanent nach dem Wert (Pull-Prinzip).
compare_exchange_strong und compare_exchange_weak
std::atomic<bool> und alle weiteren vollständigen oder partiellen Spezialisierungen von std:.atomic unterstützen inbesondere die Operation compare_exchange_strong. compare_exchange_strong ist die zentrale Operation für atomare Datentypen. Die Funktion besitzt die Syntax: bool compare_exchange_strong(T& expected, T& desired). Da die Operation in einer atomaren Operation einen Wert vergleicht und ihn gegebenenfalls tauscht, wird sie gern als compare_and_swap (CAS) Operation bezeichnet und ist in vielen Programmiersprachen zu Hause.
Ein Aufruf der Form atomicValue.compare_exchange_strong(expexcted, desired) genügt der folgenden Strategie. Falls der atomare Vergleich von atomicValue mit expected true ergibt, wird in der gleichen Operation atomicValue durch desired ersetzt. Falls nicht, wird expected durch atomicValue ersetzt. Der Grund, das die Operation compare_exchange_strong explizit als strong bezeichnet wird, ist recht naheliegend. Es gibt auch ein compare_exchange_weak-Methode. Diese weak-Variante kann aber zufällig (spurious) fehlschlagen. Das heißt, obwohl *atomicValue == expected ist, gibt die weak-Variante false zurück. Daher wird die Bedingung typischerweise in einer while-Schleife geprüft: while( !atomicValue.compare_exchange_weak(expected, desired) ). Der Grund für die weak-Variante ist Performanz. Auf manchen Plattformen ist die weak-Variante schneller als die strong-Variante.
Wie geht's weiter?
Weiter geht es im nächsten Artikel mit dem Klassen-Template std::atomic. Die verschiedenen Spezialierungen für integrale Typen und Zeiger besitzen ein deutlich reichhaltigeres Interface als der atomare Wahrheitswert std::atomic<bool>.
 Go to Leanpub/cpplibrary "What every professional C++ programmer should know about the C++ standard library". Hole dir dein E-Book. Unterstütze meinen Blog.
Go to Leanpub/cpplibrary "What every professional C++ programmer should know about the C++ standard library". Hole dir dein E-Book. Unterstütze meinen Blog.






Weiterlesen...