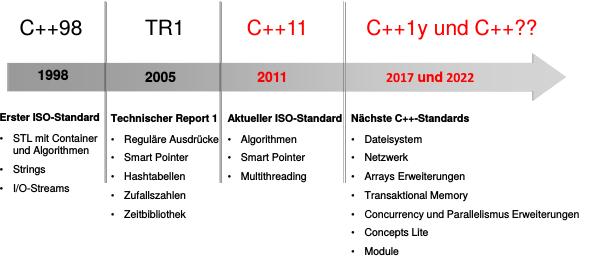
Seit C++11 stellt sich C++ den Anforderungen der Multicore-Architekturen. Der 2011 veröffentlichte Standard definiert, wie sich ein C++ Programm bei mehreren Threads zu verhalten hat. Dabei setzen sich die C++11 Multithreading-Fähigkeiten aus zwei Komponenten zusammen. Das ist zum einen, das definierte Speichermodell, das ist zum anderen, die standardisierte Threading-Schnittstelle.
Das definierte Speichermodell
Das defininierte Speichermodell ist die notwendige Grundlage dafür, dass sich Multithreading Programme in C++ definiert verhalten. So beschäftigt sich das definierte Speichermodell mit den folgenden Fragen.
- Was sind atomare Operationen?
- Welche Ordnung von Operationen ist gewährleistet?
- Wann sind Speichereffekte von Operationen sichtbar?
Zu 1. Atomare Operationen sind Operationen, die den ersten drei Buchstaben des berühmten ACID-Idioms aus der Datenbankentheorie folgen. Atomare Operationen sind atomar (A), gehen von einem konsistenten (C) Zustand in den nächsten und werden isoliert (I) ausgeführt. Das heißt insbesondere, kein anderer Thread kann einen Zwischenzustand einer atomaren Operation beobachten. Schön lässt sich die Konsistenz und Isoliertheit an einer Inkrementierung der Form atomVar++ verdeutlichen. Falls atomVar eine atomare Variable ist, so kann atomVar nur den alten oder den neuen um 1 erhöhten Wert besitzen. Die Konsistenz der Variable atomVar besteht darin, dass sie von einem nur in den anderen Zustand wechseln, die Isoliertheit, dass ein anderer Thread keinen Zwischenwert beobachten kann.
Zu 2. Sowohl der Compiler, der das Programm in Assembleranweisungen übersetzt, als auch der Prozessor, der die Assembleranweisungen ausführt, können die Operationen umordnen. Meist geschieht dies aus Performanzgründen. Zuletzt besitzen die verschiedenen Speicherebenen (Caches) auch noch die Möglichkeit, die Ergebnisse der Operationen verzögert zur Verfügung zu stellen.
Zu 3. Da es durchaus sein kann, dass ein Thread eine Operation auf einer Speicherstelle später sieht als ein anderer Thread, gilt es hier, definierten Regeln zu folgen.
Die standardisierte Threading-Schnittstelle
Die standardisierte Threading-Schnittstelle in C++11 setzt sich aus den folgenden Komponenten zusammen.
- Threads
- Tasks
- Thread-lokale Daten
- Bedingungsvariablen
Zu 1.Threads sind die elementaren Bausteine der Multithreading-Programmierung. Sie verrichten ihr Arbeitspaket autonom, werden mit Argumenten parametrisiert und interagieren mit anderen Threads über geteilte Variablen.
Zu 2. Tasks sind ein relativ modernes Konzept. Tasks bestehen aus zwei Komponenten, die durch einen Kommunikationskanal verbunden sind. Dabei übernimmt ein Endpunkt des Kanals die Aufgabe, das Ergebnis der Berechnung zu Verfügung zu stellen, während der andere Endpunkt diese abholt. Der Produzent wird Promise genannt, der Konsument Future.
Zu 3. Thread-lokale Daten sind Daten - wie der Namen leicht vermuten lässt -, die explizit einem Thread gehören.
Zu 4. Bedingungsvariablen erlauben es Sender/Empfänger Arbeitsabläufe zu implementieren. Dabei wartet der Empfänger auf die Benachrichtigung des Senders, damit er seine Arbeit fortsetzen kann.
Was bringt C++17 neues?
Der nächste C++ Standard ist für 2017 geplant. C++17 wird vor allem viele Erweiterungen rund um die Multithreading-Fähigkeiten enthalten, denn die bisherige Funktionalität ist sehr elementar. Diese Änderungen werden aller Voraussicht die drei folgenden interessanten Features enthalten:
- Latches und Barriers
- Transactional Memory
- Automatisch parallelisierende oder auch vektorisierende Algorithmen der Standard Template Library (STL)
Zu 1. Latches und Barriers sind den bekannten Semaphoren sehr ähnlich.
Zu 2. Transactional Memory ist vereinfachend gesprochen die ACID-Idee (wieder nur die ersten drei Buchstaben) auf Codeabschnitt angewandt. Das heißt, ein als Transactional Memory ausgezeichneter Codeabschnitt erlaubt es, auf Verdacht (optimistisch) ohne Synchronisation mit anderen Threads ausgeführt zu werden. Am Ende der Transaktion wird sein Ergebnis aber nur veröffentlicht, wenn die Ausgangsbedingungen noch zutreffen. Gelten diese nicht mehr, wird das Ergebnis der Transaktion verworfen und diese nochmals ausgeführt. Während das Locken des kritischen Bereichs mit Mutexen immer geschieht, wird bei der Transaktion der kritische Bereich nicht gelockt, dafür aber gegebenenfalls das Ergebnis verworfen. Ein kritischer Bereich ist ein Codeabschnitt, den nur maximal ein Threads zu einem Zeitpunkt betreten darf.
Zu 3. Während parallelisierende Algorithmen die Operationen auf ihren Containern auf mehrere Threads verteilen, führen vektorisierende Algorithmen ihre Operationen auf mehreren Elementen ihres Containers in einem Schritt aus.
Mein Plan
In den nächsten Artikeln werde ich die Komponenten des C++-Speichermodells und der standardisierten Threading-Schnittstelle genauer beleuchten. Dabei wird mein Fokus nicht darauf liegen, jedes Detail genau aufzuarbeiten. Die Details sind im aktuellen C++-Standard ISO International Standard ISO/IEC 14882:2014 oder auch auf der Internetressource cppreference.com sehr gut dokumentiert.
Mein Fokus wird insbesondere in den nächsten Artikeln darauf liegen, typische Fehler im Umgang mit Multithreading-Programmen mit modernen C++ zu zeigen und Lösungen vorzustellen. Dazu werde ich soviel Theorie einfließen lassen, um das Problem und dessen Lösung zu verstehen. Los geht es mit der standardisierten Threading-Schnittstelle.
Wie geht's weiter?
Im nächsten Artikel beschäftige ich mich mit dem Erzeugen von Threads.
 Go to Leanpub/cpplibrary "What every professional C++ programmer should know about the C++ standard library". Hole dir dein E-Book. Unterstütze meinen Blog.
Go to Leanpub/cpplibrary "What every professional C++ programmer should know about the C++ standard library". Hole dir dein E-Book. Unterstütze meinen Blog.






Weiterlesen...