Pipes and Filters
Um was gehts
Das Pipes and FiltersArchitekturpattern beschreibt die Struktur für Systeme, die Datenströme verarbeiten.- Pipe and Filters:

Beispiele
- TCP/IP Stack
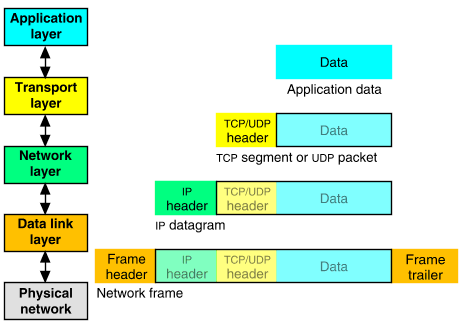
Das Pipes and Filters Muster ergänzt das LayersPattern auf natürliche Art, interpretiert man die Schichten als Filter und den Datenfluß als Pipe.
- Unix Pipes
find -name "*.py" -type f | xargs wc -l | sort | less
- Python Strings
>>> source="dies ist ein Dest"
>>> senke=source.capitalize().replace("dest","Test")+"."
>>> print senke
Dies ist ein Test.
Problem
Ein Eingabestrom soll manipuliert werden. Dies kann nicht in einem Transformationsschritt implementiert werden, da- mehrere Entwickler beteiligt sind.
- mehrere Einzelschritte notwendig sind.
- die Anforderungen sich ändern werden.
- der Austausch von einzelnen Prozessschritten
- einzelne Prozesskomponenten ansprechen
- kleine, klar definierte Prozessschritte
- nur benachbarte Filter sollten Daten austauschen
- verschiedene Datenquellen und -senken unterstützen
- Parallelverarbeitung zu ermöglichen
Lösung
Strukturiere dein Gesamtsystem in Layers. Verbinden jede benachbarte Filter (Layer) mit einer Pipe (Datenfluß). Implementiere für jeden Filter einen Ein- und Ausgabekanal.Struktur
Filter
- sind die verarbeitenden Komponenten des Systems
- er modifiziert die Daten
- reagiert auf Ereignisse
- der nachfolgende Filter entnimmt Daten
 pull Prinzip
pull Prinzip - die vorhergehende Filter übergibt Daten push Prinzip
- läuft in einer Schleife, indem er sein Daten einer Queue entnimmt
- der nachfolgende Filter entnimmt Daten
- während die ersten zwei Varianten passiv sind, entnimmt der Filter die Daten aktiv aus der Queue und stellt sie dort auch wieder zu Verfügung
Pipe
- aktive Filter werden gerne über die Pipe synchronisiert, da der Filter erst wieder bei gefüllter Queue seine Arbeit aufnimmt Producer Consumer Pattern
Datenquelle
- liefert eine Folge von Daten derselben Struktur
Datensenke
- sammelt die Ergebnisse zusammen
Datenfluß
Es existieren mehrere Möglichkeiten den Datenfluß zu steuern.- push Prinzip
- die Filteraktivität wird durch die Übergabe der Daten des vorherige Filters gestartet
- der (n-1)-te Filter schickt (write Operation) Daten an den n-ten Filter
- Datenquelle als Initiator
- pull Prinzip
- die Filteraktivität wird durch das Anfordern von Daten des nachfolgenden Filters gestartet
- der n-te Filter fordert (read Operation) Daten vom (n-1)-ten Filter
- durch sukzessives anfordern vom Daten werden diese letztendlich von der Datensquelle geliefert, so daß die Prozessierung ähnlich dem push Prinzip vollzogen werden kann
- Datensenke als Initiator
- gemischtes push/pull Prinzip
- der n-te Filter fordert einerseits explizit die Daten vom (n-1)-ten Filter an übergibt sie dann auch explizit an den (n+1)-ten Filter
- der n-te Filter ist der einzige aktive Filter in der Verarbeitungskette
- n-te Filter als Initiator
- aktive Filter als eigenständige Prozesse
- jede Filter stellt einen eigenständigen Prozeß/Thread dar, der Daten von der vorherigen Queue liest oder auf die folgende Queue schreibt
- der n-te Filter kann erst Daten lesen, wenn der (n-1)-te Filter Daten auf die verbindende Queue geschrieben hat
- der n-te Filter kann erst seine Daten schreiben, wenn der (n+1)-Filter die verbindende Queue gelesen hat
- die Struktur ist unter dem Namen Producer/Consumer bekannt
- jeder Filter kann Initiator sein
Implementierung
- teile die Gesamtaufgabe in Einzelschritte
- jede Stufe darf nur von der vorherigen Stufe abhängen
- definiert man die Stufe durch eine Interface erreicht man maximale Flexibilität
- definiere für jeden Datenkanal das Format der zu verarbeitenden Daten
- definiere insbesondere ein eindeutiges Zeichen für das Ende der Eingabe
- entscheide, wie die Kanäle implementiert werden
- von passiven Filtern werden die Daten entweder ( pull Prinzip ) angefordert oder diese werden im übergeben ( push Prinzip )
- explizite Datenkanäle wie Pipes, Fifos oder Queues erlauben im Zusammenhang mit aktiven Filtern größere Flexibilität, denn zwischen den verbunden Producern und Consumern kann eine n:m Beziehung umgesetzt werden
- will man die Reihenfolge der Filter beliebig permutieren, setze diese gleiche Datenkanäle voraus
- entwerfe und implementiere die Filter
- für passive Filter bieten sich write Funktionen ( push Prinzip) oder read Funktionen ( pull Prinzip ) an
- aktive Filter werden gerne durch eigene, leichtgewichtige Prozesse implementiert
- der Durchsatz des Gesamtsystems hängt insbesondere vom Kontextwechsel zwischen den Prozessen und der Puffergröße des Datenkanals ab
- durch die Parametrierung der Filter wird eine bessere Wiederverwendung ( vgl. sed Editor ) erreicht
- entwerfe die Fehlerbehandlung
- Mehrere Fragen müssen beantwortet werden.
- In welchem Zustand ist ein Datensatz, falls er die Filter nur teilweise durchlief?
- Ist ein Datensatz korrumpiert, läßt sich dann die Filterkette neu starten?
- Sollen Ausnahmen in Filtern korrigiert oder ignoriert werden?
- Wie bleiben die Daten im definierten Zustand, da sie gleichzeitig von mehreren Prozessen bearbeitet werden können?
- Die Schwierigkeit der Fehlerbehandlung liegt darin begründet, daß es keinen globalen Zustand der Pipeline-Komponenten gibt, sondern nur Unterzustände der Kanäle und Filter.
- Mehrere Fragen müssen beantwortet werden.
- stelle die Verarbeitungs-Pipeline zusammen
- ein Kommandointerpreter vereinfacht die Zusammenstellungs des Workflows (vgl. Command Shell)
Auswirkungen
Vorteile
- Daten werden unmittelbar weitergeleitet
 keine Zwischendateien notwendig
keine Zwischendateien notwendig - Filter einer Stufe implementieren das gleiche Interface Austausch von Filtern möglich
- Filter bieten das gleiche Interface an Neuordung oder Ergänzung der Filterkette
- Filter besitzen ein universelles Interface Wiederverwendung der Filter und Rapid Prototyping
- Filter läuft in einem eigenen Prozeß Performancegewinn
Nachteile
- Nutzung von Zustandinformation ist teuer und unflexibel
- Parallelverarbeitung ist teuer
- Übertragung der Daten ist aufwändiger als deren Bearbeitung
- manche Filter können nicht inkrementell arbeiten, sondern benötigen die ganze Datenmenge ( vgl.sort )
- der Kontextwechsel zwischen den Prozessen ist teuer
- falls der Puffer des Datenkanals zu klein ist, muß der Filter häufig gestartet werden
- um das universelle Interface zu unterstützen werden die Daten häufig formatiert (z.B.: Datenflußformat in)
- schwierige Fehlerbehandlung
Anwendungen
- Streams
- UNIX Command Shell
- ACE Stream Framework






Weiterlesen...