Die Existenzberechtigung von std::string_view ist es, kopieren zu vermeiden, falls die Daten bereits jemand anders gehören und diese nur lesend verwendet werden. Ganz einfach, in diesem Artikel geht es um Performanz.
Heute geht es wieder um ein Hauptfeature von C++17.
Ich nehme an, dass du std::string_view bereits ein wenig kennst. Falls nicht, lies den früheren Artikel C++17: Was gibts Neues in der Bibliothek? durch. Ein C++-String ist ein dünner Wrapper um Daten, die auf dem Heap liegen. Daher passiert es sehr häufig, dass eine Speicheranforderung stattfindet, wenn du mit C-Strings oder C++-Strings arbeitetest. Das will ich gerne genauer betrachten.
Small string optimisation
In ein paar Zeilen wirst du sehen, warum ich den Abschnitt small string optimisation genannt habe.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
// sso.cpp #include <iostream> #include <string> void* operator new(std::size_t count){ std::cout << " " << count << " bytes" << std::endl; return malloc(count); } void getString(const std::string& str){} int main() { std::cout << std::endl; std::cout << "std::string" << std::endl; std::string small = "0123456789"; std::string substr = small.substr(5); std::cout << " " << substr << std::endl; std::cout << std::endl; std::cout << "getString" << std::endl; getString(small); getString("0123456789"); const char message []= "0123456789"; getString(message); std::cout << std::endl; } |
Ich habe in den Zeilen 6-9 den globalen operator new überladen. Daher können wir einfach nachvollziehen, wann das Programm Speicher anfordert. Das ist aber einfach. In den Zeilen 19, 20, 28 und 29 wird Speicher angefordert. Hier sind die Zahlen:
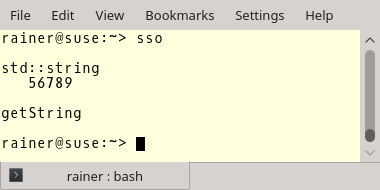
Was ist denn da los? Ich behauptete, der String speichert seine Daten auf dem Heap. Das ist aber nur richtig, wenn der String eine Mindestgröße besitzt. Die Mindestgröße hängt von der Implementierung ab. Für MSVC und GCC ist sie 15 und für Clang 23 für std::string.
Das bedeutet konkret, dass kurze Strings (small strings) direkt im String Objekt gespeichert werden. Daher ist natürlich keine Speicheranforderung notwendig.
Von nun an werden meine Strings immer mindestens 30 Zeichen groß sein. Damit muss ich mir nicht mehr über small string optimisation Gedanken machen. Jetzt geht es nochmals los mit längeren Strings.
Keine Speicheranforderung notwendig
Nun glänzt std::string_view ganz hell. Im Gegensatz zu std::string fordert std::string_view keinen Speicher an. Hier ist der Beweis.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
// stringView.cpp #include <cassert> #include <iostream> #include <string> #include <string_view> void* operator new(std::size_t count){ std::cout << " " << count << " bytes" << std::endl; return malloc(count); } void getString(const std::string& str){} void getStringView(std::string_view strView){} int main() { std::cout << std::endl; std::cout << "std::string" << std::endl; std::string large = "0123456789-123456789-123456789-123456789"; std::string substr = large.substr(10); std::cout << std::endl; std::cout << "std::string_view" << std::endl; std::string_view largeStringView{large.c_str(), large.size()}; largeStringView.remove_prefix(10); assert(substr == largeStringView); std::cout << std::endl; std::cout << "getString" << std::endl; getString(large); getString("0123456789-123456789-123456789-123456789"); const char message []= "0123456789-123456789-123456789-123456789"; getString(message); std::cout << std::endl; std::cout << "getStringView" << std::endl; getStringView(large); getStringView("0123456789-123456789-123456789-123456789"); getStringView(message); std::cout << std::endl; } |
Nochmals. Speicheranforderungen findet in den Zeilen 24, 25, 41 und 43 statt. Aber was passiert in den entsprechenden Zeilen 31, 32, 50 und 51? Keine Speicheranforderung!
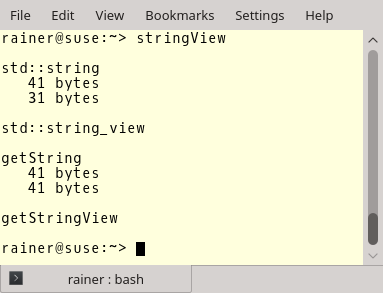
Das ist beeindruckend! Du kannst dir vorstellen, was für einen Performanzboost das ist, da Speicheranforderung eine sehr teure Operation ist. Du kannst die Performanzboost deutlich beobachten, wenn du Teilstrings aus bestehenden Strings erzeugst.
O(n) versus O(1)
std::string und std::string_view besitzen beide die Methode substr. Die Methode des std::string gibt einen Teilstring zurück; die Methode std::string_view gibt einen View auf einen Teilstring zurück. Das hört sich nicht so spannend an. Aber es gibt einen entscheidenden Unterschied zwischen beiden Methoden. std::string::substr besitzt lineare Komplexität. std::string_view::substr besitzt hingegen konstante Komplexität. Das bedeutet, das die Performanz der Methode des std::string direkt von der Größe des Teilstrings abhängt. Hingegen ist die Methode des std::string_view unabhängig von der Größe des Teilstrings.
Nun bin ich aber neugierig. Da mache ich doch gleich einen kleinen Performanztest.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
// substr.cpp #include <chrono> #include <fstream> #include <iostream> #include <random> #include <sstream> #include <string> #include <vector> #include <string_view> static const int count = 30; static const int access = 10000000; int main(){ std::cout << std::endl; std::ifstream inFile("grimm.txt"); std::stringstream strStream; strStream << inFile.rdbuf(); std::string grimmsTales = strStream.str(); size_t size = grimmsTales.size(); std::cout << "Grimms' Fairy Tales size: " << size << std::endl; std::cout << std::endl; // random values std::random_device seed; std::mt19937 engine(seed()); std::uniform_int_distribution<> uniformDist(0, size - count - 2); std::vector<int> randValues; for (auto i = 0; i < access; ++i) randValues.push_back(uniformDist(engine)); auto start = std::chrono::steady_clock::now(); for (auto i = 0; i < access; ++i ) { grimmsTales.substr(randValues[i], count); } std::chrono::duration<double> durString= std::chrono::steady_clock::now() - start; std::cout << "std::string::substr: " << durString.count() << " seconds" << std::endl; std::string_view grimmsTalesView{grimmsTales.c_str(), size}; start = std::chrono::steady_clock::now(); for (auto i = 0; i < access; ++i ) { grimmsTalesView.substr(randValues[i], count); } std::chrono::duration<double> durStringView= std::chrono::steady_clock::now() - start; std::cout << "std::string_view::substr: " << durStringView.count() << " seconds" << std::endl; std::cout << std::endl; std::cout << "durString.count()/durStringView.count(): " << durString.count()/durStringView.count() << std::endl; std::cout << std::endl; } |
Lass mich erst ein paar Worte zu dem Performanztest verlieren, bevor ich die Zahlen präsentiere. Die zentrale Idee des Performanztests ist es, eine große Datei als std::string einzulesen und eine Menge von Teistrings mit Hilfe von std::string und std::string_view zu erzeugen. Ich bin genau daran interessiert, wie lange das Erzeugen der Teilstrings benötigt.
Ich verwendete "Grimms Märchen" als große Datei. Name verpflichtet! Der String grimmTales (Zeile 24) besitzt den Inhalt der Datei. Danach fülle ich in Zeile 37 den Vektor std::vector<int> mit einer access Anzahl (10'000'000) von Werten zwischen [0, size - count - 2] (Zeile 34). Nun kann der Performanztest los gehen. In den Zeilen 39 bis 41 erzeuge access Teilstrings der festen Länge count. Der count ist 30. Daher muss ich mir keine Gedanken zu small string optimisation machen. Dasselbe tue ich nochmals in den Zeilen 47 bis 49. Dieses Mal aber mit std::string_view.
Hier sind die Zahlen. Du siehst die Länge der Datei, die Zahlen für std::string::substr und std::string_view::substr und das Verhältnis zwischen beiden. Als Compiler verwendete den GCC 6.3.0.
Größe 30
Nur bin ich neugierig. Hier sind die Zahlen ohne Optimierung..
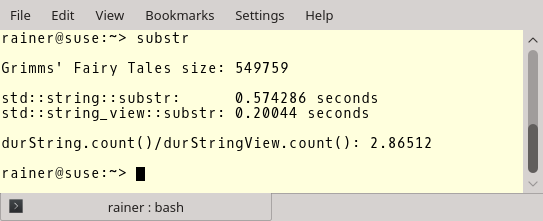
Jetzt kommen aber die wichtigen Zahlen. GCC mit maximaler Optimierung.
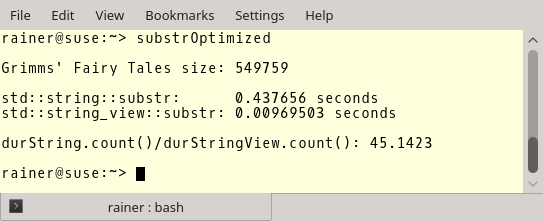
Die Optimierung zahlt sich im Falle des std::string nicht so aus, macht aber einen großen Unterschied beim std::string_view. Teilstrings mit std::string_view zu erzeugen ist rund 45 Mal schneller als mit std::string. Falls das kein Grund ist std::string_view zu verwenden.
Verschiedene Größen
Nun werde ich aber noch neugieriger. Was passiert, wenn ich die Größe count des Teilstrings variiere? Jetzt gibt's alle Zahlen noch mit maximaler Optimierung. Ich habe sie auf die dritte Nachkommastelle gerundet.
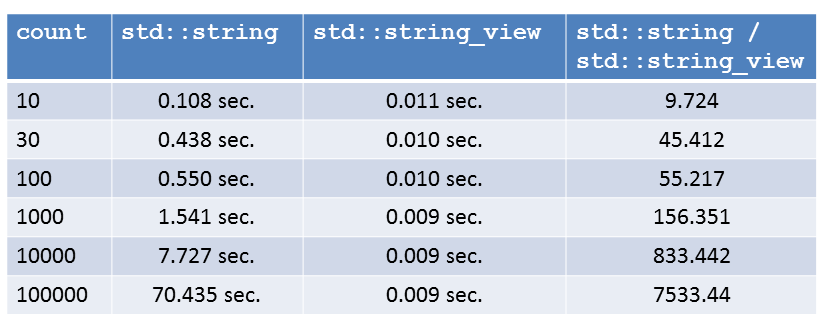
Das hat mich nicht verwundert. Die Zahlen spiegeln die Komplexitätszusicherungen von std::string::substr versus std::string_view::substr wider. Die Komplexität der ersten Methode hängt direkt von der Länge des Teilstrings ab. Die Komplexität der zweiten Methode ist unabhängig von der Größe des Teilstrings. Am Ende überflügelt die Performanz des std::string_view die des std::string sehr deutlich.
Wie geht's weiter?
Ich habe noch einiges über std::any, std::optional und std::variant zu sagen. Warte auf den nächsten Artikel.
 Go to Leanpub/cpplibrary "What every professional C++ programmer should know about the C++ standard library". Hole dir dein E-Book. Unterstütze meinen Blog.
Go to Leanpub/cpplibrary "What every professional C++ programmer should know about the C++ standard library". Hole dir dein E-Book. Unterstütze meinen Blog.






Weiterlesen...